当社は過去10年以上に渡り、その当時の最新技術で実現可能な最高レベルの音声UIを構築してきました。これらのノウハウを元に、当社の音声UI構築ソリューションでは、高い全体性能を持ち「現場で実際に役に立つ」音声応用システムをお客様と共に実現します。



現代の音声UXでは、従来と比較して解くべき問題が格段に難しくなってきています。例えば、環境騒音80dBを超えるような超高騒音環境や、屋外のデジタルサイネージのようにマイクと発話者の距離が遠い環境で高い精度の音声認識を実現することや、多言語での自然な発話への対応、GUIを超えた直観的体験性の実現などが挙げられます。ニューラルネットワーク技術の発展に伴ってAIの性能が大きく高まってきたことによって、遂に人間にとって真に自然な音声UXを実現するレベルに至ってきたとも言えるでしょう。
当社は過去10年以上に渡り、その当時の最新技術の範囲で実現できる最高レベルの音声UIを構築してきました。当時の個別の認識エンジンは現代のような高い性能を持たない場合も多く、顧客体験を損なわない範囲でビジネス要件を再整理して制約条件を付けることや、周辺技術によって全体性能を引き上げるような様々な工夫を行ってきました。これらのノウハウや経験は、現代の難しい課題を解く上でも依然有効です。
当社の音声 UI 構築ソリューションでは、個別の認識エンジンの性能を最大限発揮させ、高い全体性能を持ち、現場で実際に役に立つ音声応用システムをお客様と共に実現します。ここでは代表的な事例として、スマートフォン、多言語音声に対応したデジタルサイネージ、音声対話ができるサービスロボット、そしてウェアラブル端末による音声点検システムなどの事例をご紹介します。

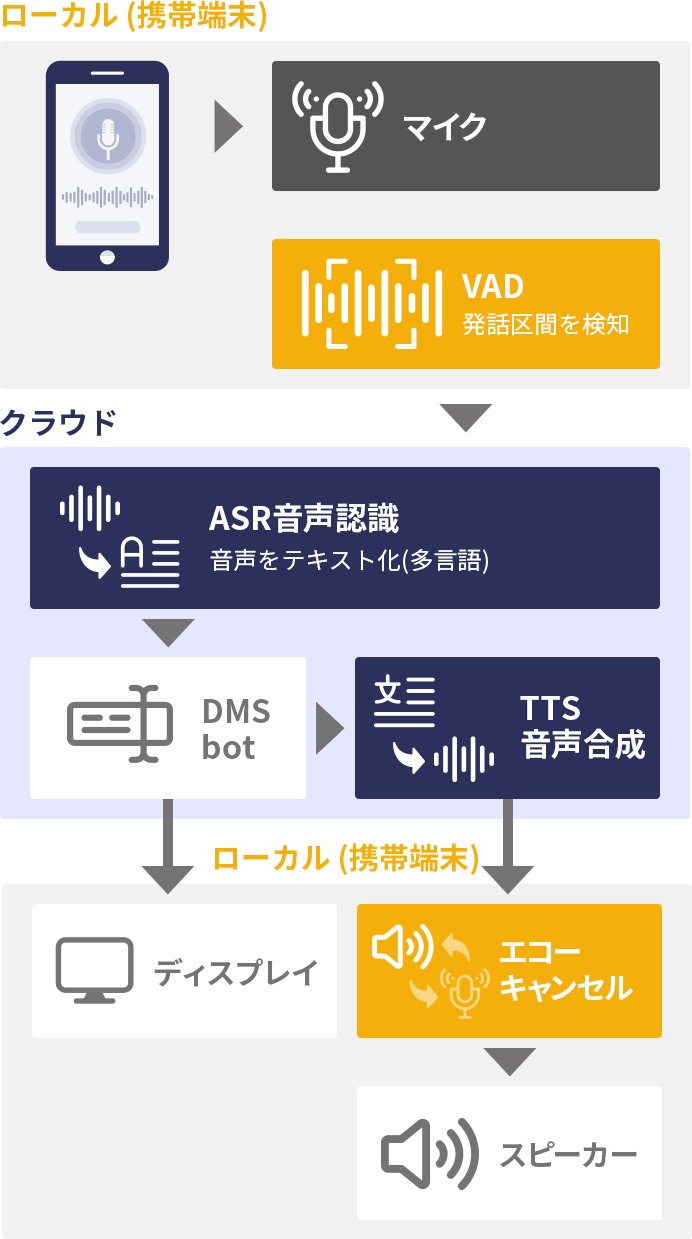
スマートフォン上での基本的な対話アプリの構成例です。まず、スマートフォンのマイクから取得された音声は、VAD (Voice Activity Detector) により人間の発話区間だけが抽出されます。抽出された発話音声は、ウェイクワード認識器 によって、事前に登録されたウェイクワードであるか否かが判定されます。ウェイクワードとは、例えば「オーケーグーグル」のように、対話アプリを開始(ウェイクアップ)させるためのキーワードのことを言います。このような仕組みは「ボイスウェイクアップ」と呼ばれます。
マイクのオン・オフと VAD の使い方については、「端末マイクをコントロールする典型的な3つの UI」 の解説もご覧ください。ウェイクワード認識を通過後、クラウド側では事前に指定された言語で音声認識がなされます。VAD により発話開始が検出された時点から、音声データは発話中にも逐次的に送信されているため、音声認識エンジンは逐次的に認識処理を行います。
スマートフォンアプリの場合は利用者が固定されているため、話者識別 は利用されない場合もあります。ただし、事前登録者以外の発話に反応しないために話者識別を利用することがあるのと、ペットロボット等の場合は、誰が話しかけたか?という情報が適切な応答生成のために重要であるため、話者識別機能が利用されます。
音声認識と同時に、音声態度認識、音声感情認識 が実行されます。これらの非言語情報を認識し、対話エンジンに送り込むことで、対話エンジンがより適切な応答を生成できるようになります。
これら一連の認識結果は対話エンジンに送られます。いわゆるチャットボットと呼ばれる部分であり、ルールベースのシンプルなシステムから、Google Dialogflow や ChatGPT 等の大規模言語モデルに基づく高度な対話システムなどを利用することができます。この部分は、mimi®標準サービスでは提供しておらず、当社研究開発チームにて個別に対応をいたします。
発話者の感情や態度などの非言語情報に合わせた応答を生成することが対話システムの親密度を高めることが知られています。これらは業務ニーズに合わせて作りこむこともできますが、最近では大規模言語モデルに対するプロンプトエンジニアリングの文脈で非言語情報を入力として取り扱うこともできるため、対話システムはますます親しみやすい応答を返すことが期待できます。
最後に、音声認識結果や対話応答文については必要に応じて端末の画面表示を行い、音声合成して端末のスピーカーから再生します。音声再生時には、エコーキャンセラー により、再生音がマイクに回り込むことを防ぐ必要があります。この処理がないと、利用者は合成音声の再生完了まで、次の発話を待たなければならず利便性が極端に悪化します。いわゆるバージインに対応することは最近の対話システムでは必須です。
「オーケーグーグル」などのウェイクアップワードで対話システムが開始するとき、話者識別機能が使われないと、誰の声であっても対話システムが起動できることになります。今、この原稿を書いている会社のオフィスで私が大声で「オーケーグーグル」などと叫べば、多くの同僚たちのスマートフォンでグーグルアシスタントが起動してしまうでしょう。
スマートスピーカーなどでも同様の問題が発生します。このため、利用者が決まっているスマホアプリ等においても、話者識別機能を有効化して、そのウェイクワードが本人が発話したものであるかどうかを確認することは有効です。
ただし、話者識別機能は、いわゆるバイオメトリクス認証の分野に属する「話者認証」機能ではありません。このため、ウェイクワードを録音した音声を再生するだけで本人の発声であると識別します。上記の用途で利用する場合には厳密な話者認証は必要なく、話者識別で必要十分であるということになります。
携帯端末において、マイクが常にオン(always-on)であり常時録音されている音声を、そのまま通信でクラウドに送信するというのは通信量やクラウド計算資源の無駄であり、プライバシー保護の観点からも好ましい仕組みとはいえません。このため、always-on システムでは、クラウドに送るべき音声とそうではない音声をデバイス上で選別する仕組みが必要です。
ウェイクワード認識はこの目的のためにデバイス上で利用されます。常時処理を行う必要があるため、ウェイクワード認識器(KWS)は軽量・高速・低消費電力で動作することが求められ、SoC メーカーによっては、音声コーデックチップ上でハードウェア実装として提供している例もあります。
技術的な視点からは、VAD が人間の声であるか否かを判定するだけであるのに対し、KWS はさらに特定のワードであるかどうかを判定する機能を持ったものであると理解することができます。

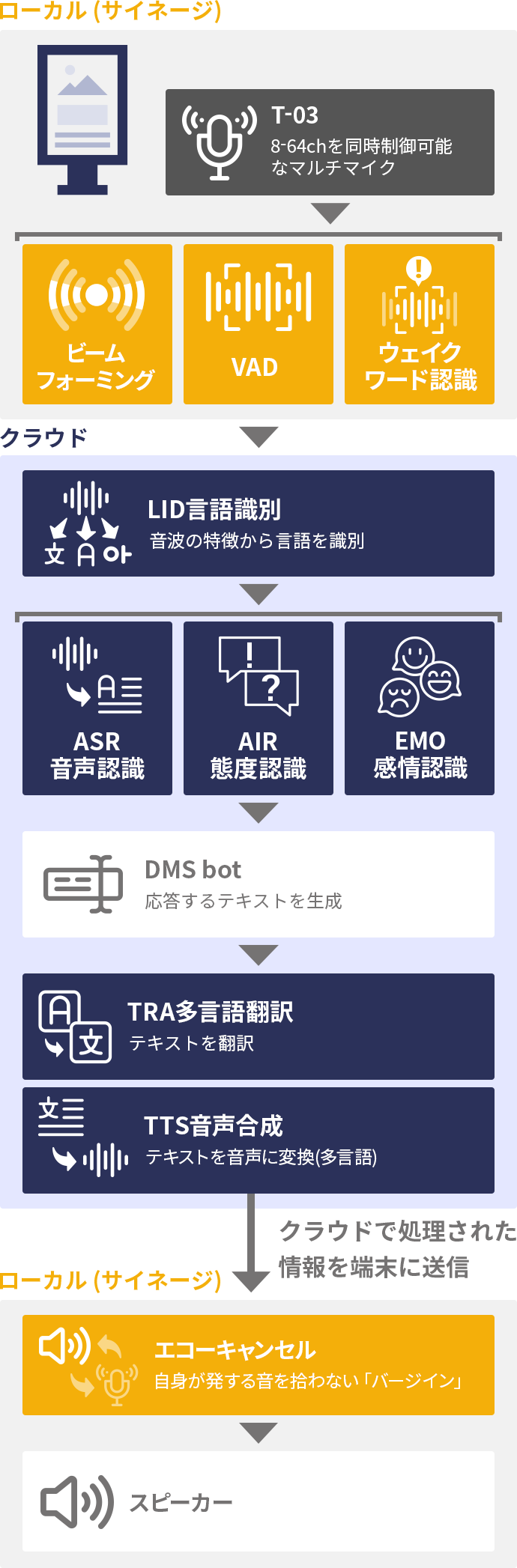
多言語での音声操作に対応したデジタルサイネージの典型的な構成例です。これは例えば、屋外や大型商業施設・駅構内等に設置された、多言語で音声案内したり質問に回答したりするデジタルマップ、キオスク端末、自動券売機などが含まれます。
まず、マイクのハードウェアとして、T-03C 等のマイクアレイを利用します。通常の単一マイクでは、駅構内や商業施設内等の周辺騒音の大きい環境で実用的な音声認識性能を得ることは困難です。このため、当社製であるか否かを問わず、マイクアレイ機能を利用することは事実上必須と言えます。 音声対応サイネージに、昔の電話機のような「受話器」が設置されている例もありますが、ハンズフリーであることが音声対応システムの大きな利点であるにも関わらず、そのような受話器が設置されているということは自己矛盾しており、誰も積極的に利用したいとは思わないでしょう。
タクシーやバス等の車載で利用されるタブレット端末等も同様です。車内には走行音やエンジン音等があり、平均的には中程度のノイズ環境といえます。タブレット端末に搭載されている単一マイクでは、状況によっては十分な音声認識性能が出ない場合があります。これに対して、タブレット端末の上部にマイクアレイを設置するだけで、口元をタブレットに近づけることなく、深く座った状態でも十分な音声認識性能を期待することができます。
デジタルサイネージでは、利用者の位置は必ずしも固定的ではなく、サイネージと利用者の位置関係は様々な要因により変化します。利用者の位置をカメラにより認識する場合や、カメラは利用せず入力音声のみから音源位置を推定するように構成する場合などがあります。この部分の詳細については、サービスロボットの構成例も合わせてご覧ください。
利用者の位置が推定できれば、ビームフォーミング等の音声強調処理によって、周辺雑音が抑圧された利用者のクリアな発話音声がクラウドに転送されます。 スマートフォンアプリやスマートスピーカーでは、ボイスウェイクアップが利用されますが、公衆端末ではウェイクアップワードを事前に利用者に伝えることができないため使われることはありません。
クラウド側では、まず mimi®LID により、その発話が何語であったかが判定されます。携帯端末アプリケーションの場合は、アプリのユーザーが事前に言語を設定することができるため、そのような言語自動識別は不要となりますが、公衆端末では、何語で話しかけられるかは分からず、言語設定をさせる UI は煩雑になるため、言語識別機能は本質的に重要な機能となります。
mimi®LID で判定された言語で音声認識された文字列は、次に日本語に翻訳されます。ここで日本語に翻訳する理由は、その後段で音声対話を行うチャットボットに日本語で入力するためです。大規模言語モデルに基づく ChatGPT 等の最近のチャットボットシステムにおいて言語の差が内部的に吸収できる場合にはこのような明示的な事前翻訳は不要となりますが、簡単なルールベースシステムや Google Dialogflow のようなチャットボットにおいては日本語のみで開発・保守を行うことが容易であるので、 チャットボットに入力する前段で日本語に翻訳を行います。ここで重要なことは、このような仕組みとすることで、チャットボットの実現方式によらず、日本語のみの対応で自動的に多言語にも対応できるということです。 チャットボットへの入力に、態度や感情などの非言語情報を与えることで、より適切な応答が生成できるという点も、スマートフォンアプリの構成例と同様です。チャットボット部分は mimi®標準サービスでは提供しておらず、当社研究開発チームにて個別に対応をいたします。
チャットボットが生成した応答文を改めて元の入力言語に翻訳し、さらに音声合成した後、端末側に送り返して再生します。このとき、端末上でエコーキャンセルを行うことが極めて重要であることはスマートフォンアプリの場合と同様です。これは、端末で再生した音声が、端末のマイクに回り込むことを防止する処理です。これによって、端末で音声再生中にも、端末はユーザーの音声命令を受け付け続けることができるようになります。この仕組みがないと、端末から応答音声が再生されている間中、ユーザーは何の音声命令も与えられずに長時間待たされるため、ユーザーを苛立たせることに繋がります。いわゆるバージインへの対応であり、現代の音声応答システムにおいては必須の機能です。
スピーカーについては任意のスピーカーを利用することができますが、公衆端末においては、複数のスピーカーを利用するなどして可能な限り指向性を持たせることがより好ましいと言えます。また、空気中ではなく端末筐体内部を通って来る振動(固体伝搬)はエコーキャンセルでは取り除きにくい信号であるため、スピーカーとマイクアレイとの間で、固体伝搬を低減するような音響分離設計を行うことがより好ましいと言えます。
バージイン発話とは、システムが発話中(音声再生中)に、利用者がその発話を遮って(かぶせて)新たに音声命令を発話することをいいます。この発話に対応できていないと、システムの発話が終わるまで利用者は次の音声命令を与えられず、待つことしかできません。これはとても不便です。
システムが間違った応答をしてしまい、それを訂正したいとき。システムの応答が長く、途中で止めたいとき。音楽の再生中に音声命令を与えたいときなど、バージイン発話が発生する状況はたくさんあります。当社では EC(エコーキャンセラー) によって、バージイン発話への対応を行っています。
バージイン発話に対応することは、現代の音声対話システムにおいては必須の機能であると言えます。

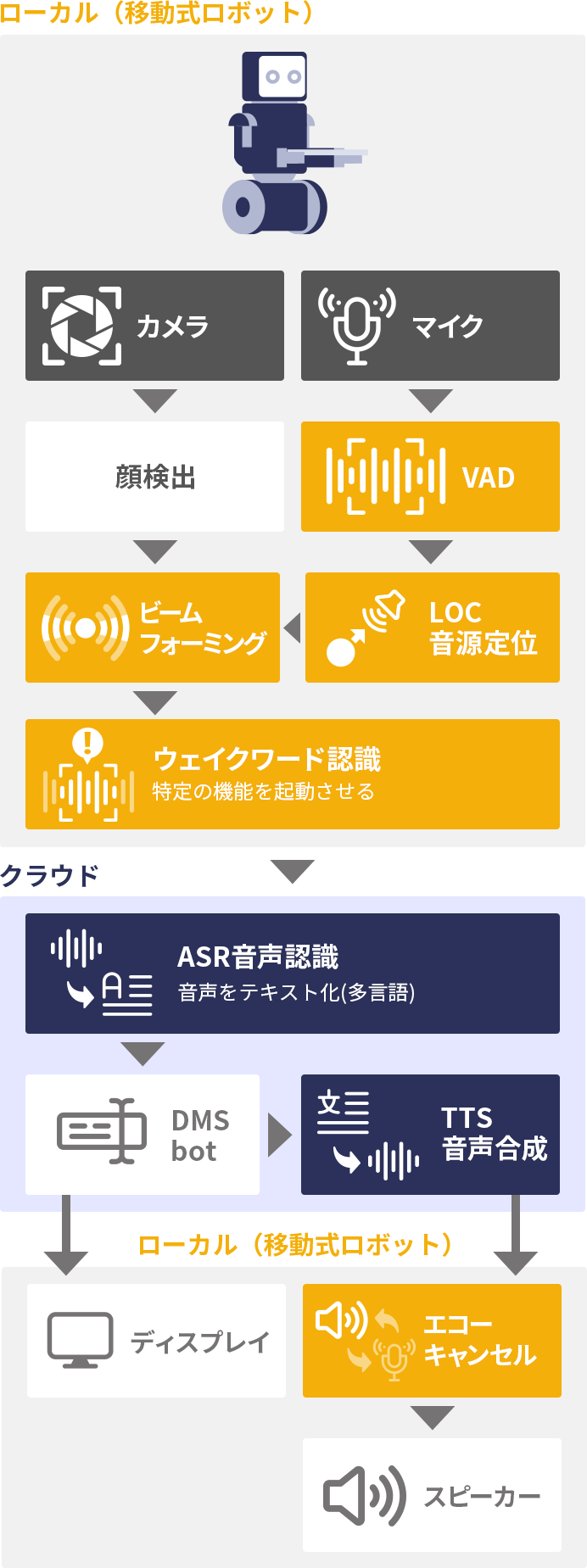
ファミリーレストランや居酒屋チェーンの配膳ロボットや、大規模施設の警備ロボット、病院やホテルの搬送ロボットなど、私たちの身近な空間で使われるサービスロボットの現場導入が進んでいます。これらのサービスロボットに音声対応を追加する構成例を紹介します。この構成例は、ほぼ、多言語音声対応デジタルサイネージの構成例と同じであるので、内容の詳細はそちらも合わせてご覧ください。ここでは、移動するサービスロボットに特有の観点を紹介します。
固定式のデジタルサイネージは概ね正面方向にユーザーがいることを前提にできますが、移動式のロボットではユーザーとの位置関係が全く固定されていません。いきなり後ろから話しかけられることもあるでしょう。ここで LOC による音源定位機能により、後ろから話しかけられていることを検出することは可能です。しかしながら、それがロボットに向けられた発話であるか、後ろで人間同士が会話しているのかを区別することは容易ではありません。複数の手がかりから総合的に判断する必要があります。例えば、後ろから「すみません」「ロボットさん」などと呼びかけられたときのみにロボットに対する発話であると判断するといった組み合わせが必要です。手がかりを増やすために、360度の視野角を持つカメラを搭載することも有効です。顔検出技術によって、呼びかけた人がロボットの方を向いているかどうか、という手がかりをさらに加えることができます。
顔検出技術は、話しかけられているかどうかを判定するためだけではなく、ロボットに対する親和性を向上させるためにも利用されます。「顔」や「目」を持つロボットの場合、ユーザーとの対話中に、「顔」や「目」をユーザーの方に向けることによって、対話している感を向上させ、ひいてはロボットに対する親和性を向上させることにつながります。音源定位機能だけでは、ユーザー位置の特定精度が甘く、ロボットの顔や目を推定方向に向けたとしても、実際のユーザーの位置とは若干ズレることがあり、対話感を向上させるには至らない場合があります。これに対して、カメラによる顔検出の場合は、より高精度にユーザーの位置を特定することができます。
カメラに複数人が同時に写っている状況で、そのうち誰が発話したかを判定したいときには、顔検出と音源定位を組み合わせることで実現することができます。実際に発話している人の方向に、ビームフォーミング技術等によって指向性を形成することで、他の方向からのノイズを大きく抑制し、発話者の音声のみをクリアに集音することができます。これはレストランのように常にざわざわしている環境ではほぼ必須機能であり、移動式ロボットの場合はさらに、駆動系(モーターや歯車)のノイズを低減する上でも役に立ちます。
ユーザーは発話中に、自らの発話がロボットに受理されているかどうかが不安になります。受理されていることを示す上で、人間同士であれば表情の変化や頷きなどの仕草や相槌などで示すことができますが、ロボットの場合に、そのような細かい変化を精度よく実行させることは未だ実用的であるとは言えません。一般的にはディスプレイ上に、音声を受理していることを表示することで代替しますが、ディスプレイが無い場合には、大型の LED の色や点灯パターンの変化などで表現することも可能です。例えば、駅案内ロボットの事例では、特徴的な「目」の周りを一周取り囲む LEDリングの色と点灯パターンの変化で音声受理状態を表現していますし、スマートスピーカーでも同様の LED リングが用いられます。これらの即時的な表現を行うときには、音声認識結果を待つ時間的余裕はありませんので、VAD などエッジ側に搭載され低遅延に動作する特徴量抽出器の出力結果を利用します。
その他の処理は、他のパターンと同様であり、自動言語識別や多言語音声認識・合成機能を利用します。スピーカー側に EC を利用したエコーキャンセル処理を組み合わせることで、バージイン対応とすることも同様であり、対話ロボットには必須の機能であると言えます。
ロボットに対して話しかけられているかどうかを判断する上で顔検出技術が有効であり、複数の顔が検出されたときに、どの人が発話しているかどうかは LOC を組み合わせることで判断することができるということを前述しました。さらに、映像だけでも唇の動作を見ることでさらに手がかりを得ることができるでしょう。では唇の動作を検出できる認識器を追加しましょう… このように、複数のモジュールを多段で積み上げていくことで性能を向上させてくことができます。そのどこかの段階で実用精度に至れば工学的には問題ないと言えるでしょう。
研究の世界では、このように多段で別モジュールを積み上げるのではなく、ひとつの問題として解くことで根本的に性能を上げる取り組みがなされています。画像と音声を統合的に学習する技術は、「マルチモーダル学習」、又は「Audio Visual Learning」等と呼ばれる研究分野であり、映像と音声をまとめて入力できるひとつの大きなニューラルネットワークを使って、End-to-End で認識結果を得るという仕組みです。話者分離(Speaker Dialization)の研究では、ニュース番組のように2人の人間が正面で映っている動画を入力として、誰がいつ発話しているかを特定してそれぞれの声を単独で取り出すという研究があります。音源分離の他の研究例では、ロックバンドの演奏動画から、いつどの楽器が鳴動したかを特定し、ミックスダウンされた楽器音から個別の楽器音を分離して取り出すといった研究があります。これらの研究も Audio Visual Learning の研究分野に位置づけられるものです。
工学的に役に立つものを作る上で、複数モジュールを組み合わせて性能を上げて応用します。研究はそれらを End-to-End になるようにまとめあげていきます。SMT から NMT に進化して翻訳精度が上がったように、ひとつにまとめ上げることができれば、まとめられた部分の性能は向上する可能性があります。研究と応用はこの繰り返しで進歩しており、現状は組み合わせが必要な部分も、将来的にはひとつのモジュールで実行できるようになるかもしれません。最近の例としては、ChatGPT等の大規模言語モデルが画像を取り扱うことができるようになりつつあることもこのひとつの形と言えるでしょう。
mimi®標準サービスには Audio Visual Learning 分野の研究成果は未だ取り込まれていませんが、この分野の研究は急速に発展しており、今後のサービスロボットの実世界への応用には重要なキーテクノロジーとなるでしょう。

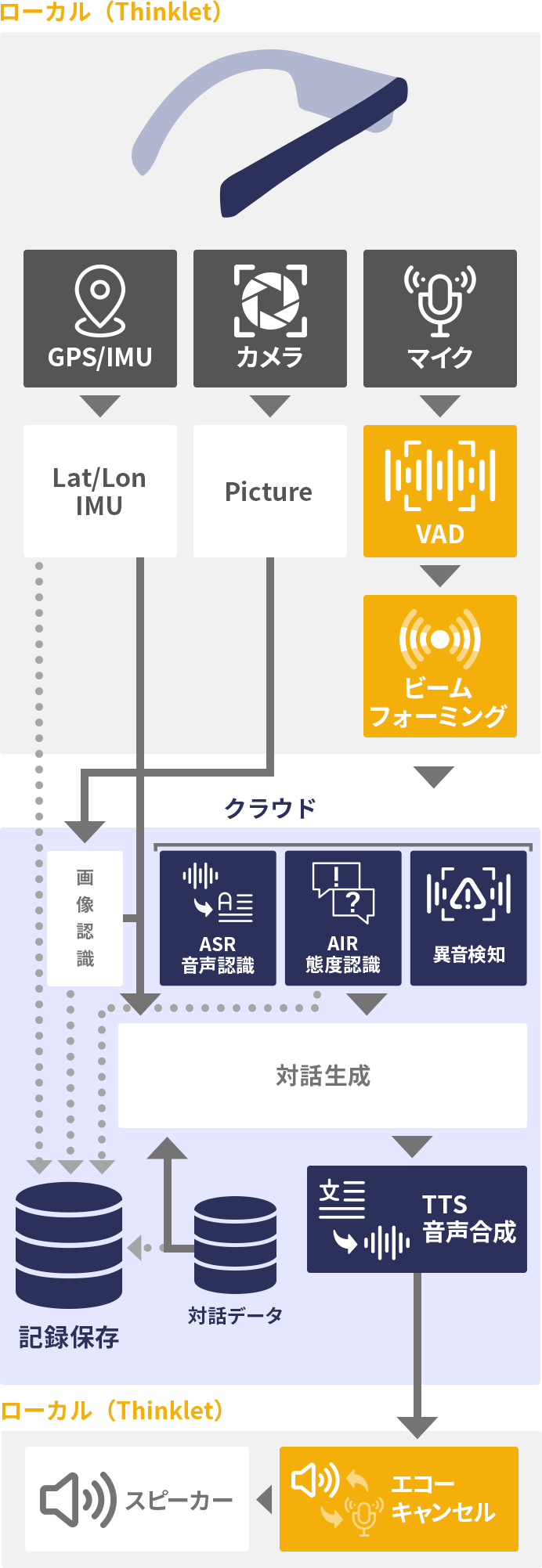
ウェアラブル端末において音声対話システムは非常に重要な応用用途のひとつです。この構成例では代表的な利用事例として、プラント設備等を点検する際に、音声入力で点検作業を行うことができる「音声設備点検/音声帳票システム」の構成例を紹介します。
設備機器の点検作業では、従来はタブレット端末等を利用して点検結果の入力作業を行っていましたが、音声点検システムではこれを音声発話で代替することでより短時間で点検作業を完了することが可能になります。危険な区域などでは保護手袋が必要な場合もあり、音声点検システムはタブレット端末が利用できない環境でも有効です。 点検から一歩進んだ保守・修理作業では、作業完了後に修理報告書を作成しなければなりません。従来であれば、事務所に戻ってからパソコンで一から修理報告書を作成する必要がありましたが、ウェアラブル端末が導入されていれば、修理中に修理内容等を発話しておくことで、修理報告書が半分程度完成した状態から仕上げのみ行うだけで済むようになるという効果があります。
この構成例では、当社のウェアラブルデバイスである THINKLET® を利用します。THINKLET は他のウェアラブルデバイスには見られることの少ないマイクアレイと広角カメラを搭載し、現場の高騒音環境下でも頑健に動作するという特徴があります。THINKLET を利用しなくても、適切に設計されたハードウェアであれば、環境騒音 80dB クラスの超高騒音環境下においても、一定の音声認識性能を達成することが可能でしょう。
まず、THINKLET のマイクアレイで収録された音声は、人間の発話部分が抽出された後、音源定位 により、装着者の発話音声であるかどうかが判定されます(装着者の口元の方向からの発話であるかどうかが判定されます)。装着者の音声であると判定されたとき、ビームフォーミングによって、装着者の発話音声のみを強調し、周辺雑音を大きく抑制する処理が行われます。
この音声はクラウドに送信される前に、ウェイクワード認識器によって、ウェイクワードであるかどうかを判定する構成とする場合があります。これは例えば「OK THINKLET」や「音声点検開始」などのキーワードによって、音声点検作業を開始する場合などに利用される構成です。ただし点検作業内容や手順によって、必ずしも常にこの構成になるわけではありません。
クラウドに送信された音声は、THINKLET に事前設定されている言語で音声認識されると同時に、用途に応じて音声態度認識や音声感情認識が実行されます。現場では、その会社のみに通用する略語や特殊な用語が数多く登場するため、音声認識辞書にもそのような特殊語を追加する必要があります。 また、喜怒哀楽の範囲を超えた、現場作業特有の「感情」を検知することが有効である場合があります。例えば「慌てている感情」を識別することで、安全を向上させる効果があります。「驚いている感情」を検知することは、ヒヤリハット事例の自動収集に役立ちます。mimi® の音声感情認識では、このような感情を「カスタム感情」として識別させることができます。
ここまでは音声側の話となりますが、THINKLET には装着者の視野の大半を撮像できる広角カメラも搭載されています。音声点検作業中にはこのカメラ映像も利用します。THINKLET のような身に着けるカメラや視線カメラから得られる映像のことを、一人称視点映像と呼びます。この一人称視点映像の解析・認識技術は近年急速に発展している分野の一つであり、一人称視点動画から、装着者の動作意図を推定する研究を中心に当社でも積極的に研究開発を進めています。 音声点検作業で発話された内容と、撮影された映像を自動的に組み合わせることで、音声点検作業を効率化することや、より適切な点検帳票を作成することができるようになります。
例えば、端子台に色の異なるケーブルが配線されているような場合、どの端子にどの色のケーブルが接続されている状態が正しいのか、といったことは人間が判断する場合、マニュアルを読んでひとつひとつ確認して…と時間の掛かる作業です。画像認識であれば、一瞬で判断できることであり、圧倒的な時間短縮に繋がります。
THINKLET には同様に GPS や IMU(姿勢センサー)も搭載されているため、石油化学コンビナートなど屋外の広大な施設を点検するときにはこれらのデータも合わせて記録しておくことが有効です。
そして、これらの全てのデータは、チャットボットに入力させることが可能です。定形的な音声点検作業の場合、画像認識結果、GPS 情報、発話内容等から定形的なルール(シナリオ)を事前に作りこむこともできますし、より高度なチャットボットシステムを利用することも可能です。ローカルな業務データに紐づく正確な応答を返さなければならないため、ChatGPT のような大規模言語モデルを利用することは現時点では困難ですが、この分野の研究開発は世界的に進展しています。 当社の研究開発チームにて、お客様の作業内容に合わせた最適な提案を行うことができます。

多言語対応の音声案内サイネージに利用可能です。単にサイネージに話しかけるだけで動作するため直観的に利用できます。

自社アプリの中に高度な翻訳機能を埋め込むことができます。チャットツールへの翻訳機能の追加は特に利便性を高めます。

バスやタクシー等の座席に設置されているタブレット端末を多言語音声に対応させることが可能です。

透明ディスプレイやタブレット端末等の窓口に設置できるタイプの非接触型翻訳システムとして利用することができます。

組み込み翻訳機能のないウェブ会議システムや、独自の通信システム等に外部的に音声翻訳機能を付与することができます。

導入事例
mimiエッジAIとクラウドAIの多くの機能を活用した駅構内・周辺案内業務用コミュニケーションロボットです。多くの人が行きかう雑踏騒音環境でも、目の前の人の声だけを聞き取り正確な応答を実現しています。話しかけた言語は自動で識別され、多言語での応答を行うことができます。これにより駅員の質問対応業務時間を削減することに成功しました。
オムロンソーシアルソリューションズ株式会社
詳しく見る
導入事例
mimiエッジAIとクラウドAIの多くの機能を活用したデジタルサイネージ向けの音声対話システムです。多くの人が行きかう雑踏騒音環境でも、目の前の人の声だけを高速かつ正確に聞き取り、画面表示と連動した分かりやすく親しみやすい応答を実現しています。
株式会社モノゴコロ
詳しく見る