当社の音声翻訳ソリューションは、国内トップレベルの言語対応数を持つ音声翻訳システムを、お客様システムに組み込むことができるソリューションです。ここでは代表的なソリューション事例をご紹介します。





近年、ニューラル機械翻訳の性能向上に伴って自動翻訳技術は実用性能を達成し、ますます普及が進んでいます。mimi®︎ が提供するコアテクノロジー群を利用することで、ビジネスにも活用できる高性能な音声翻訳システムをお客様のシステムに組み込むことが可能です。代表的な事例として、スマートフォン、窓口翻訳システム、ウェアラブルデバイス、そして一般のアプリケーションにも適用可能な方式としてビデオ会議システムの事例をご紹介します。

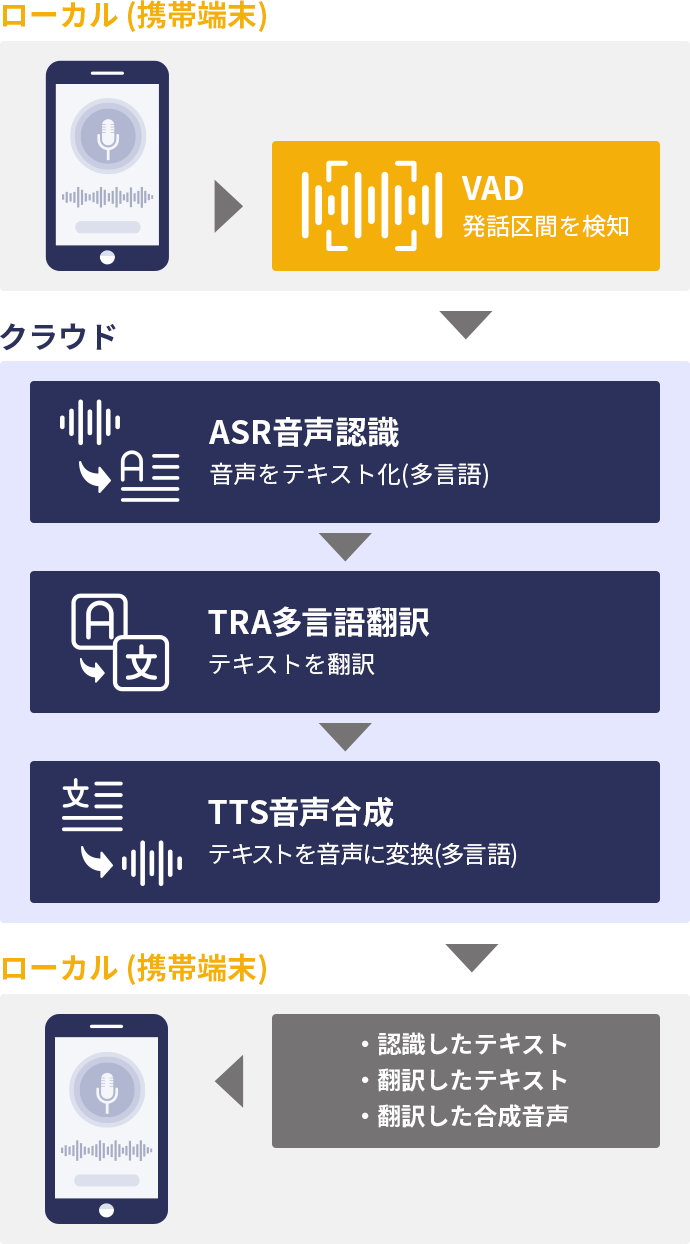
スマートフォン等のアプリに音声翻訳機能を組み込むときの最も基本的な構成例です。まず、スマートフォン等のマイクから収録された音声は、 VAD (Voice Activity Detector) により人間の発話区間だけが抽出され、クラウドにリアルタイムに送信されます。VAD を使わずに Push to Talk 方式を採る場合もありますが、詳細は下の囲み記事をご覧ください。
クラウドに送信された音声は、音声認識・機械翻訳され、翻訳結果がテキストとして端末に返されます。端末はテキストを画面表示すると同時に、改めてクラウドに音声合成リクエストを送信し翻訳音声を再生します。上の説明図では省いていますが、さらに 逆翻訳インターフェース を追加する場合、最初の翻訳結果が返された時点で、音声合成リクエストと同時に逆方向の翻訳リクエストをもう一度クラウドに送信することになります。
このような基本的な音声対話アプリケーションの開発でも、録音から画面表示、画面操作、APIリクエスト等の複数のタスクが同時並行になされることで、素早い応答性能を維持します。当社では、この構成例を実装した mimi音声翻訳アプリ を公開しています。

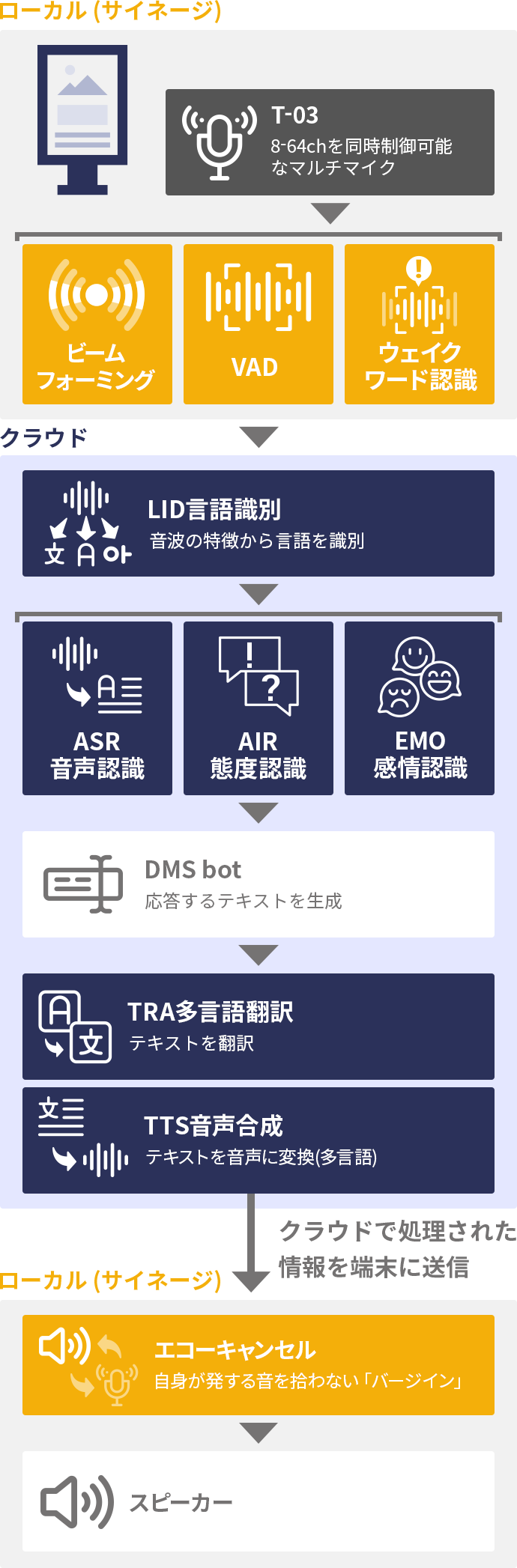
切符売り場などの固定的な窓口や、タクシーの座席に設置されたタブレット端末等、据置型の翻訳システムの利用が進んでいます。それらの「窓口翻訳システム」の典型的な構成例です。
まず、マイクのハードウェアとして、T-03C 等のマイクアレイを利用します。通常の単一マイクでは、駅構内や商業施設内等の周辺騒音の大きい環境で実用的な音声認識性能を得ることは困難です。このため、当社製であるか否かを問わずマイクアレイ機能を利用することは事実上必須と言えます。音声対応サイネージに、昔の電話機のような「受話器」が設置されている例もありますが、ハンズフリーであることが音声対応システムの大きな利点であるにも関わらず、そのような受話器が設置されているということは自己矛盾しており、誰も積極的に利用したいとは思わないでしょう。
タクシーやバス等の車載で利用されるタブレット端末等も同様です。車内には走行音やエンジン音等があり、平均的には中程度のノイズ環境といえます。タブレット端末に搭載されている単一マイクでは、状況によっては十分な音声認識性能が出ない場合があります。これに対して、タブレット端末の上部にマイクアレイを設置するだけで、口元をタブレットに近づけることなく、深く座った状態でも十分な音声認識性能を期待することができます。
マイクアレイによるビームフォーミング等の音声強調処理によって、周辺雑音が抑圧されたクリアな音声がクラウドに転送されます。 窓口の場合には、利用者が立つ場所は固定的であることが期待できるためビームフォーミングの指向性方向も固定することができますが、さらに音源定位を利用することで、利用者以外の発話を無視することができるようになり窓口係員側の利便性が向上します。
クラウド側では、まず mimi® LID により、その発話が何語であったかが判定されます。携帯端末アプリケーションの場合はアプリのユーザーが事前に言語を設定することができるため、そのような言語自動識別は不要となりますが、公衆端末では何語で話しかけられるかは分からず、言語設定をさせる UI は煩雑になるため、言語識別機能は本質的に重要な機能となります。
mimi® LID で判定された言語で音声認識された文字列は、次に日本語に翻訳され、窓口係員に画面表示で提示されます。画面表示のために半透明ディスプレイを利用する場合も最近では多く見られるようになりました。窓口翻訳システムでは、翻訳結果が音声合成されることは典型的にはありません。
mimi® EMO により、利用者側の感情を認識することができます。コールセンター等でも同様のシステムが見られますが、例えば「怒り」の感情を認識することで、上級管理者に素早く窓口の異常事態を伝達することができるようになります。
窓口係員の発話については、日本語であることが固定されていること以外についてはこの逆の流れとなりますが、窓口係員側のマイクについては設置環境に応じて複数の選択肢があります。ひとつのマイクアレイをお客様発話・窓口係員発話の双方に共用できる場合もありますし、別々のマイクアレイ、通常のスタンドマイクやヘッドセットを利用する場合もあります。

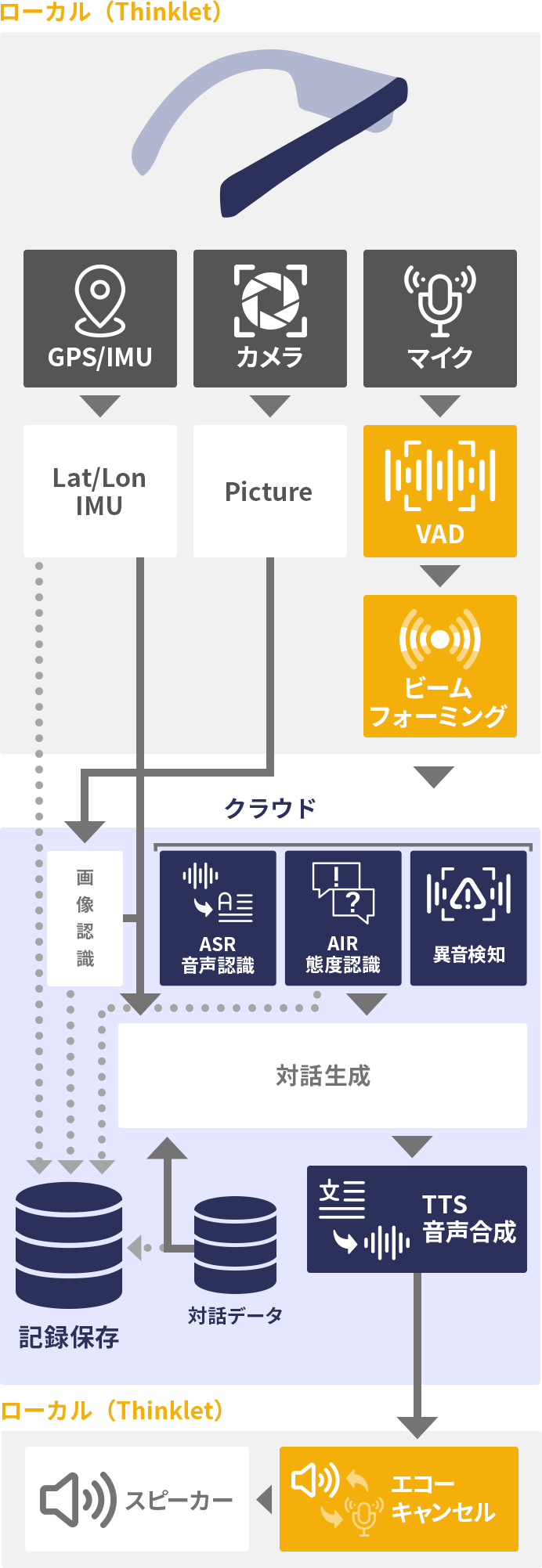
複数台のウェアラブル端末(もしくはスマートフォン等)を通信で結ぶことにより、ハンズフリーの同時通訳器として利用することができます。
それぞれのウェアラブル端末には事前にユーザーの母国語が設定されており、どの端末間を通信で結ぶかという端末のグループ化は、何らかの方法で事前に決定されているとします。例えば Bluetooth等の近距離無線通信や、QRコードを用いて端末同士を特定するといった方法が利用されます。ここでは、日本語話者と英語話者の2名がいるものとしましょう。
まず、日本語話者の音声はウェアラブル端末のマイクで集音され、VAD によって発話区間のみが抽出されてクラウドに送信され、音声認識と英語への翻訳がなされます。翻訳された文字列は英語で音声合成され、相手の端末のスピーカーから再生されます。これは、再生するべき音声のアドレスをメッセージキューを通して相手の端末に伝達することでなどで実現することができます。このとき、日本語話者の端末でも合成された英語音声を再生する(上記点線矢印)ことが翻訳体験として有効であることもあります。
音声再生には、ウェアラブル端末のスピーカー又はイヤホンを用います。イヤホンの場合は問題ありませんが、スピーカーの場合には、再生した音がマイクに回り込むことを防ぐためにエコーキャンセル機能が必要となります。
上の説明図では、当社のウェアラブル端末である THINKLET®︎ を利用しています。THINKLET は 5ch マイクアレイを搭載しており、ビームフォーミング等の音声強調処理 や、音源定位 を利用することで、周辺雑音を大きく低減させ、自分の声以外の音声を拾わない(近くの別の発話者の声は入らない)ため、ユーザーの利便性が大きく向上します。
THINKLET を利用しなくても同様のシステムを構成することは可能です。ただし、周辺雑音に弱くなることで、周りがうるさい環境で認識・翻訳精度が低下したり、近くの他の話者の発話を拾ってしまうことで対話が成立しにくくなるなどの懸念があり注意が必要であると言えます。
サーバーサイドの翻訳方式として、逐次翻訳の場合、自分が発話し翻訳された後、ほぼ同じ時間を掛けて翻訳言語で音声再生され、相手がそれを聞き応答する、という流れになりますので、1回のやり取りに少なくとも発話時間の2倍以上(機械翻訳の処理時間を加えるとさらに長い)の時間がかかることになります。同時翻訳であれば、自分の発話中に、翻訳された結果を相手が聞き始めるので、機械翻訳の処理時間を加えても、1回のやり取りは発話時間の 2 倍以下の時間で完了することになります。このように通信を利用した翻訳器の場合、同時翻訳の効果は高いと言えます。

ZOOM や Microsoft Teams 等に代表される一般的なビデオ会議システムに対して、外付けで音声翻訳機能を追加することができる構成例です。最近では、ビデオ会議システム自体に音声翻訳機能が内蔵されている場合もあるため、必ずしも mimi のような外部サービスを利用する必要はありませんが、このような構成を取ることで、既成のアプリケーションに手を加えず音声翻訳機能を付加できるという点で有効な構成例です。
この構成例では、仮想マイクドライバを利用します。まず、物理マイクから入力された生音声が他の構成例と同様に音声翻訳され、翻訳結果の合成音声が返されます。この合成音声を仮想マイクドライバに与えるというところがポイントです。
一般のアプリケーションでは、普通の「マイク」として、この仮想マイクドライバを選択することができ、仮想マイクドライバからは、翻訳結果の合成音声が流れてくるため、既成アプリケーションに対して手を加えずに外付けで音声翻訳機能を加えることができるということになります。 言い換えれば、「音声翻訳機能がついたマイク」をソフトウェア的に実現しているということになります。
ただし、逐次翻訳の場合、合成音声が再生されるまでに遅延が発生するため、リアルタイム用途には十分ではない場合があります。他の構成例として、仮想ビデオドライバを利用した字幕生成に留め、合成音声は利用しないという構成も有効です。
上図の緑色部分は自由にプログラムを作ることができる部分です。音声処理として VAD を使うなど他の構成例と同様の処理を行いますが、このような形で仮想ドライバを利用することで、一般のアプリケーションに与える音声と映像を自由に加工することができるため、音声翻訳に留まらないさまざまな活用が可能になります。

多言語対応の音声案内サイネージに利用可能です。単にサイネージに話しかけるだけで動作するため直観的に利用できます。

自社アプリの中に高度な翻訳機能を埋め込むことができます。チャットツールへの翻訳機能の追加は特に利便性を高めます。

バスやタクシー等の座席に設置されているタブレット端末を多言語音声に対応させることが可能です。

透明ディスプレイやタブレット端末等の窓口に設置できるタイプの非接触型翻訳システムとして利用することができます。

組み込み翻訳機能のないウェブ会議システムや、独自の通信システム等に外部的に音声翻訳機能を付与することができます。

導入事例
mimiエッジAIとクラウドAIの多くの機能を活用した駅構内・周辺案内業務用コミュニケーションロボットです。多くの人が行きかう雑踏騒音環境でも、目の前の人の声だけを聞き取り正確な応答を実現しています。話しかけた言語は自動で識別され、多言語での応答を行うことができます。これにより駅員の質問対応業務時間を削減することに成功しました。
オムロンソーシアルソリューションズ株式会社
詳しく見る
導入事例
mimiエッジAIとクラウドAIの多くの機能を活用したデジタルサイネージ向けの音声対話システムです。多くの人が行きかう雑踏騒音環境でも、目の前の人の声だけを高速かつ正確に聞き取り、画面表示と連動した分かりやすく親しみやすい応答を実現しています。
株式会社モノゴコロ
詳しく見る