mimi®︎ AIR は、当社独自の研究開発に基づくユニークな認識器のひとつで、音声のパラ言語情報として表出される話し手の「態度・意図」を認識して4つのクラスに分類するサービスです。 パラ言語情報とは、音声に含まれる非言語情報のうち、話し手がイントネーションや抑揚・声色の変化などを使って、意図的に相手に伝えようとする情報のことをいいます。商用サービスとして展開されたパラ言語認識サービスは世界的にもユニークであり、音声対話システムや音声翻訳システムに応用することができます。このサービスでは、入力された音声を4つの態度に分類します。言語依存性が高いものであり、標準サービスでの対応言語は日本語のみとなります。
このサービスで識別する4つの態度・糸は、以下のように定義されます。mimi AIR が識別する「態度・意図」は、話し手が発話に意図的に込めたものです。発話全体に通底する「感情」は、mimi EMO を利用することで識別することができます。
| クラス名 | ラベル | 話し手の心的状態 | 話し手が相手に期待する行動 | 句読点 |
|---|---|---|---|---|
| 肯定・平叙 | agreement | 賛成・満足・単に意見を述べている | そのまま続けてよい | 。 |
| 否定 | disagreement | 反対・不満足・想定外 | 一度止めてほしい | !? |
| 考え中 | stalling | 思索・悩み・戸惑い | いったん待ってほしい | … |
| 疑問 | question | 質問・聞き返し・事実確認 | 教えてほしい | ? |
音声に含まれるパラ言語情報をもとに認識を行うので、文字情報(単語の意味)は利用していないことに留意してください。例えば、「私は賛成です」と素直に発話したときと同じ調子(イントネーションや声色)で「私は反対です」と発話した音声は、「肯定・平叙」に分類されます。
mimi®︎ AIR は入力データがひとつの発話であると前提し、長い入力中の発話態度の変化を追跡することはできません。日本語の音声態度は、主に話し手の話終わり付近のパラ言語に表れます。このため、このサービスを利用するときには、入力音声データの終端が、実際の話終わりになることが好適です。入力音声の末尾が発話の途中であるなどした場合には、mimi®︎ AIR の結果は意味のないものとなります。
しかしながら、実際の「話終わり」を推定することは困難な場合があります。このため、入力側で XFE VAD を利用して、無音区間を使って発話を切り取って入力することになります。ただし、無音区間で発話を区切るため、区切られた箇所が、真の話終わりではない場合があります。このようなときは、さらに音声認識サービスを組み合わせます。音声認識結果は、文字情報を使って句読点を出力することができます。音声認識結果が句点「。」を出力したとき、その発話末尾は、真の「話終わり」である確率が高くなります。つまり、音声認識結果が「。」を出力した入力音声についての mimi®︎ AIR の出力のみを有効とみなすという組み合わせが有効になります。
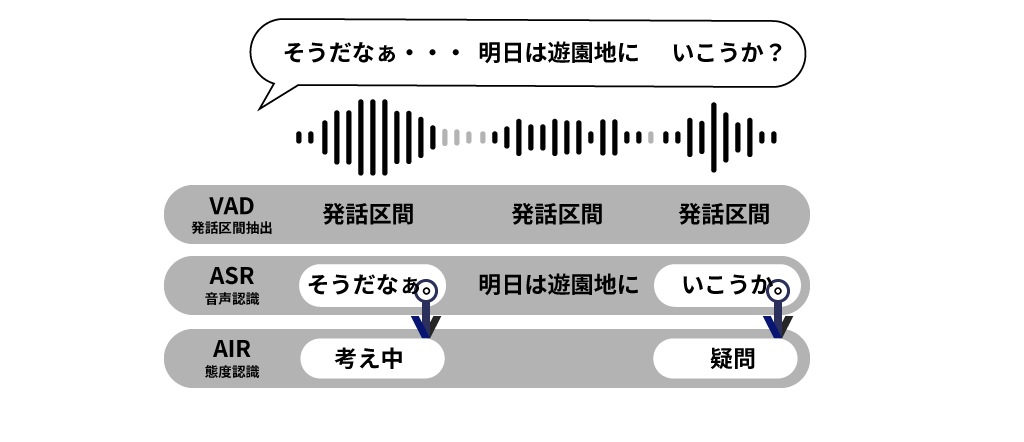
なお、mimi®︎ AIR は発話末に特に強く着目するため、話終わりの後の無音区間の長さは通常の VAD の長さよりも長め(250ms ~ 1000ミリ秒)程度を取るとより高精度の出力を得ることができます。
mimi®︎ AIR で典型的に識別されるサンプル音声はこのようになっています。このサンプル音声は演技的な音声であり、利用者が実際に発話する音声とは異なりますが、製品のチュートリアル等で、このような典型的な音声を利用者に聞いてもらうことで、態度認識結果がより明確になるという効果があります。
話し手の心理状態を識別することができますので、単純な文字起こしでは分からない人間同士の会話に含まれる態度を識別できるようになります。
音声認識では正確な意図が読み取れなかった場合に、態度認識の結果を元に対話システムの応答を決定できるようになります。例えば、「はぁ」などの短い発話がなされたときに、どのような意味の「はぁ」なのかははっきりとしません。このようなときに、システム側が毎回同じように聞き返すのではなく、態度認識の結果を元に聞き返しの内容を変えるということができます。同様に例えば、「そうか」などの発話についても、「そうか」という同意であるか「そうか?」という疑問(否定)であるかによって、対話システムの応答は真逆になるべきです。これらの例のように、対話システムの応答により人間らしい柔軟性を持たせたいときに利用することができます。


例えば「夕食にカレーを食べたい」という発話が、肯定形であるか疑問形であるかは文字情報だけでは分かりません。すなわち「食べたい。」という理解・肯定を示す発話なのか、「食べたい?」と疑問形で問いかけているのかによって、翻訳結果は全く異なるものとなるべきです。このようなときに、音声認識サービスと態度認識サービスを組み合わせ、語尾に「。」もしくは「?」を付与することで、正確な機械翻訳結果を得ることができるようになります。

mimi®︎ AIR の典型的な出力例は以下のようになります。入力された音声に対して、4つの態度のスコアが全て返されます。以下の例の場合、15行目に返されている agreement のスコアが突出して高いため、この入力音声は「同意」という態度を表していると推認することができます。
{
"type": "air",
"session_id": "12ab572a-df1c-11eb-a0c4-42010a92008e",
"status": "recog-finished",
"response": {
"time_interval": {
"start": 0,
"end": 6270
},
"label": "agreement",
"scores": {
"question": 0.0012281100498512387,
"stalling": 0.0003516068682074547,
"agreement": 0.9984184503555298,
"disagreement": 1.7658468323134002e-06
}
}
}

ログインするだけですぐに mimi®︎ クラウドAIを無償評価利用することができます。
プログラミングの知識不要。APIコンソールでは簡単な画面で試すことができます。
mimi®には、クラウド上で高度な認識処理を行うクラウドAIと、
デバイス上で高速な前段処理を行うエッジAIがあります。
mimi®︎の全体像や、mimi®︎エッジAIについて知りたい方はこちら。
 APIコンソール
APIコンソール 態度認識APIの
態度認識APIの