クラウド型オンライン音声認識APIサービスである mimi®︎ ASR は、13ヶ国語に対応した多言語連続音声認識サービスです。日本語を基軸言語として国立研究機関にて開発された純国産の多言語音声認識システムであり、特に日本語を含む東南アジア言語において高い認識性能を持っています。搭載されている汎用認識モデルは定期的に更新されており、常に新しい単語や言葉遣いを取り込んでいます。
mimi®︎ ASR には組み込み型とクラウド型の2種類があり、それぞれ異なる特徴を持っています。組み込み型は高いカスタマイズ性を持ちますが、クラウド型と比べて認識できる言語やパターンに制約があります。クラウド型はカスタマイズ性は低くなりますが、汎用性が高く制約はありません。
mimi®︎ ASR の提供するAPIを通して、Google Cloud Speech-to-Text 等、他社の音声認識サービスを利用することも可能です。mimi®︎ ASR の API に対応するクライアントアプリケーションは、プログラムを変更することなく音声認識サービスのみを切り替えることができるため、開発の手間を減らし利便性を向上させることができます。
一般的な音声認識器は、以下のような構造を持っています。マイク等から入力された連続的な音声は、音声認識器の内部でまず音響解析され音声認識エンジンに入力可能な形式のデータに変換されます。このデータを認識モデルと呼ばれる音声認識器のコア部分に入力し、出力となる発話内容テキストが推論されます。

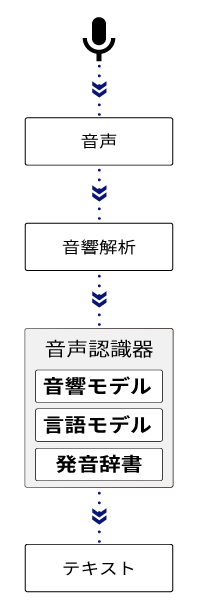
認識モデルには3つの要素があります。「音響」の要素は、音と文字を関連付ける部分です。こういう音がしたらこの文字だ、という対応を学習しています。「言語」の要素は、文章に現れる単語のパターンを学習しています。「明日の天気は…」という文章があったら、きっと次には、「晴れ」や「雨」など天気を表す単語が来るだろう、というようなことを予測することができます。最後に「発音」の要素は、たくさんの単語と、その単語の読み方が登録された大規模な辞書です。日本語には漢字がありますので読み方も登録する必要がありますが、読み方を登録しなくてよい言語もあります。
上図では、マイクから入力された音声は、直接音声認識器に与えられていますが、実際の応用場面では、フロントエンド処理(前段処理)と呼ばれる前処理が為されたのちに音声認識器に与えられる場合がほとんどです。
このとき、音声認識器の部分をバックエンド処理(後段処理)と呼ぶ場合があります。フロントエンド処理は、クラウドAIの種別によらず共通化することができるため、フロントエンド側から見れば、クラウド側はどのような認識器が搭載されていても構いません。

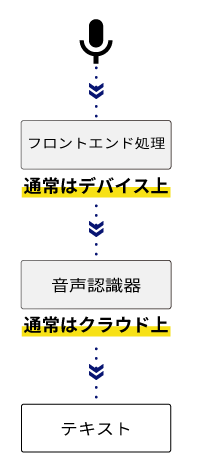
フロントエンド処理は、一般のスマートフォン等ではハードウェアとして実装されていることも一般的ですが、mimi®︎ ではフロントエンド処理をソフトウェア実装の mimi®︎ XFE として提供しています。通常、フロントエンド処理はデバイス上で実行されバックエンド処理はクラウド上で実行されますが、応用によってはフロントエンド処理の一部がクラウド側で実行される場合もありますし、その逆もあります。ハードウェア実装と比較してソフトウェア実装の方が応用に対して柔軟に対応でき、最新技術に追従しやすく性能を稼ぎやすい反面、CPU を使用するため消費電力上は不利になります。
当社では、単一のマイクではなく複数のマイク(マイクアレイ)を利用することを推奨しています。マイクアレイを利用した音声認識システムの全体像をまとめると、典型的には下図のようになります。マイクアレイから入力された多チャンネル音声信号は、フロントエンド処理によって、1ch 音声信号(モノラル音声)となり、音声認識器に入力されます。このような構造を取ることによって、ショッピングモールや駅構内、工事現場などの高騒音環境でも、高い音声認識性能を達成することができるようになります。

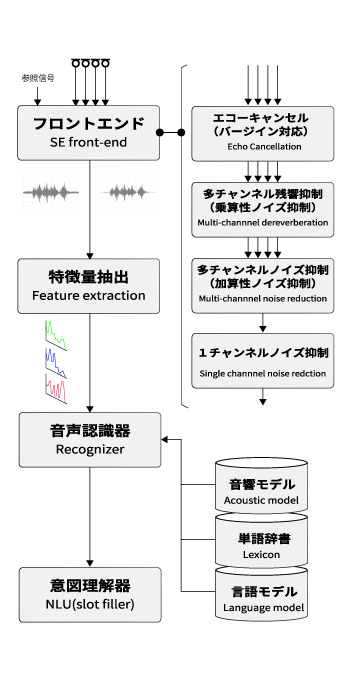
フロントエンド処理の中身は、応用によって上図とは異なる構成をとります。応用シーン別のフロントエンド処理の内部構成については、音声UI構築ソリューションの構成例も合わせてご覧ください。
mimi®︎ ASR はオンライン音声認識サービスです。ここで「オンライン」というのは、インターネットにつながっているかどうかということではありません。オンライン認識の反対語はオフライン認識ではなく、バッチ認識と呼ばれる方法です。
オンライン認識とは、逐次的に認識が進んでいく認識の仕方を意味します。人間の生の発話のスピードは、コンピューターの世界から見ると、とてもゆっくりしたスピードです。例えば、「明日の天気は晴れでしょう。」という発話であれば2秒くらいの発話時間がかかります。この発話している時間に、発話を追いかけるように同時に音声認識を行うことができれば、発話が終了した時点で、最初の方の発話内容の認識処理は終わっているため、完全な音声認識結果が出力されるまでの時間を大きく短縮することができます。
一般的なクラウド型音声認識 API サービスの多くはこのオンライン型となっています。YouTube などで、音声認識による自動字幕機能を有効にすると、発話に対してリアルタイムで認識結果が表示される様子が見られます。これがオンライン音声認識となります。
これに対して、バッチ型音声認識とは、発話がすでに終了している状態で、発話先頭から発話末尾までの音声データ全体を一括で認識する方法です。事前にたくさんの録音データがあり、一定時間をまとめて使って全ての音声ファイルの書き起こしを作る、といったときに利用される方法です。対話システム等のリアルタイムで応答を返す用途では、発話の終了まで認識器は何もせず待つことになり応答速度が遅くなってしまうため利用するべきではありません。
mimi®︎ ASR ではバッチ型の音声認識サービスは API として提供していませんが、オンライン認識器をバッチ用途に利用することはできるため(逆はできません)事前に録音された音声ファイルの書き起こし用途に活用することも可能です。
オンライン認識では、新たなデータが入力される都度都度で認識処理が進んでいきますが、一定の長めの時間、例えば2秒などの時間は入力データをバッファして、毎2秒ごとの全長を使って認識処理を逐次的に進めていく中間的な認識方式もあり、そのような方式をセミバッチ型と呼ぶことがあります。音声を文字に変換するための音声認識器においてはこのようなセミバッチ型を取ることはありませんが、mimi®︎ では、mimi® EMO(音声感情認識)でセミバッチ型を採用しています。 オンライン型では、ある時点まで入力されたデータしか解析に利用することができませんが、バッチ型では、全長のデータを解析に利用することができます。つまりある時点で未来のデータも利用できるということであり、認識対象によっては、この点が性能上有利に働くことがあります。セミバッチ型は、この2つのいいとこどりをした方式であるということができます。
音声認識が速い、遅い、と表現されることがあります。この「速さ」にはいくつかの要素がありますが、代表的な定量指標が「RTF(Real Time Factor)」と呼ばれる指標です。RTF とは、「1 秒の入力データが与えられたとき、認識処理が完了するために、その何倍の時間が掛かるか?」という指標です。つまり、以下の式で表すことができます。


1 秒の音声をバッチ的に入力したとき、音声認識の完了まで 0.5 秒掛かるとしたら RTF = 0.5 となります。逆に 2 秒かかるとしたら RTF = 2 となります。この定義から明らかな通り、RTF は小さいほど、認識器は速いということになります。
クラウド型 mimi®︎ ASR では、実用上の観点から認識器本体の RTF は概ね 0.3 ~ 0.4 前後になるように調整されています。つまり、バッチ的に音声認識する場合、認識処理のために、入力音声時間の 0.3 ~ 0.4 倍の時間が掛かるということになります。もし手元に合計 10 分の音声ファイルがあるとしたら、認識にかかる時間は 3 分~ 4 分くらいだろうと見積もることができます(ただし、音声ファイルには無音区間が含まれるため、無音区間を事前にカットすることで、この時間より短くなることがあります)。
オンライン型の認識器において、RTF は別の意味も持ってきます。RTF < 1 のときは問題ありません。入力データの長さより認識時間が短いので、新たなデータが入力される都度、そのデータに対する認識処理は、実時間で次のデータが来る前に終わっており、認識器は新たなデータを待っているという状況になります。このため、発話の長さに依存せず、発話終了時刻から認識完了時刻までの長さは一定となります。

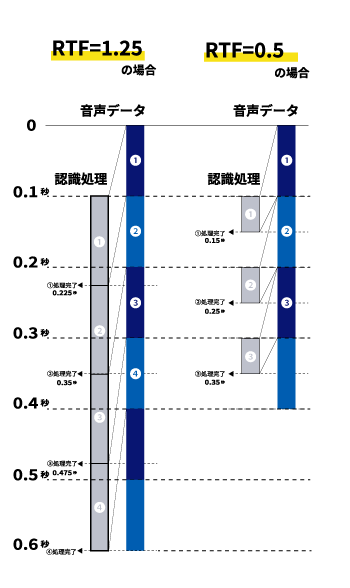
これに対して、RTF > 1 のときは問題が発生します。入力データの長さより認識時間が長いので、新たなデータが入力される都度、そのデータに対する認識処理は、実時間で次のデータが来ても終わっていません。認識器は常に認識処理を行っているということになり、実時間に間に合わなかった分がどんどん蓄積されていきます。このため、発話終了時刻から認識完了時刻までの時間は、発話長が長くなればなるほど長くなってしまいます。この超過分がシステムの容量を超えると、システムが停止したり応答を返さなくなってしまうという不具合に繋がることもあります。このため、オンライン型の認識器においては、必ず RTF < 1 になるように調整されていることが必要となります。
このように、認識器の速さを表す重要な指標である「RTF」ですが、私たち人間が体感する「速さ」には、他にも様々な要素があります。代表的な要素としては、初期遅延(初期レイテンシ)が挙げられます。これはリアルタイムで字幕を出力するような UI で見られるもので、発話開始時刻と最初の認識結果出力までのタイムラグを言います。初期遅延が小さいほど、発話開始直後に認識結果を見ることができるので、体感上速さを感じます。
この他にも、スマートスピーカーで見られた UX では、発話意図解析と応答内容の生成に掛かる時間を誤魔化すため、発話終了時に、発話終了したということのみを検知する仕組み(VAD など)を使って素早く「ポロン」といった効果音を鳴らします。これによってユーザーは、音声命令が受け付けられたのだ、という実感を得ることができ、効果音ののち数秒を待つことに心理的な不安感を感じにくくなります。この「ポロン」のあるなしは UX 上非常に重要な要素だったと言えます。

日本語を基軸として開発された
純国産音声認識エンジン クラウド型 mimi®︎ ASR は、NICT(国立研究開発法人情報通信研究機構)による長年の研究成果に基づき開発されたサービスです。日本を代表する純国産の音声認識器として日本語を基軸言語としつつも多言語対応を前提に開発されたものであり、日本語を含む東南アジア言語の音声認識においては特に高い性能を誇ります。 対応言語は13ヶ国語(日本語・英語・中国語・韓国語・ベトナム語・タイ語・インドネシア語・ミャンマー語・フランス語・スペイン語・ブラジルポルトガル語・フィリピン語)であり、多言語対応が必要となる自治体窓口やインバウンド観光業務などで幅広い利用実績があります。
機械翻訳とのサーバーサイド連動 入力言語と出力言語の指定が異なる場合、サーバーサイドで自動的に機械翻訳され、音声認識結果と共に翻訳結果も返されます。音声認識結果をクライアントに返し、その後再度翻訳リクエストを送信する場合と比較して、サーバーサイドで処理が最適化されているため高速な応答を期待することができます。

専門用語の追加機能 一般的な新語・固有名詞、新しい言葉遣いなどは定期的に取り込まれていますが、業界特有の用語や自社特有の用語など特殊な単語を追加することができます。音声認識・機械翻訳技術をビジネス応用する上で、このような専門用語を認識できることは極めて重要です。単語が登録されていないと、その単語が認識・翻訳できないだけではなく、その単語の前後も巻き込んで誤認識・誤翻訳が発生してしまうことになります。

用途に応じた高いカスタマイズ性 mimi®︎ ASR にはこのページでご紹介しているクラウド型とは別に組み込み型があります。NICT(国立研究開発法人情報通信研究機構) の研究成果に基づくクラウド型は、汎用性が高く、どのような発話でも認識できる反面、個別に細かい調整を行うことは困難です。当社独自の研究成果に基づく組み込み型は、個別に細かい調整ができ高騒音環境等でも高い認識性能が達成できる反面、認識できる発話のパターンに制約があり、多言語対応も限られたものとなります。それぞれの特徴を活かして、応用用途に応じて使い分けることができます。
mimiクラウドAIは、パブリッククラウドサービス上に構築されています。これらの一式と同様のシステムを、お客様のオンプレミス環境に構築することができます。例えば高セキュリティ用途・閉域網での利用や、外洋船舶・航空/宇宙等のオフライン環境で音声AI・翻訳機能を提供したいときに有効です。 当社ではクラウドの設計ノウハウを活かして、お客様のご要望に応じてソフトウェアから物理サーバーまで一式のシステム開発・提供をすることができますのでお気軽にご相談ください。

お客様のご要望に基づき、一般的ではない単語やフレーズを登録させることができます。日本語の場合、登録したい単語とその読み方をペアで提供いただくことで登録を行うことができます。他の言語については、登録したい単語リストのみを提供いただければ、その読み方は自動推定し登録させることができます(読み方を手動で指定させることもできます)。
用途に応じて言語モデルをカスタマイズすることで、より高い性能を達成することができます。当社では言語モデルのカスタマイズも承ることができますが、高性能な言語モデルのカスタマイズのためには、サンプルとなる文章を大量に用意する必要があり、データ作成を含めて一定の費用と期間がかかります。このため、最初のステップとしては「単語・フレーズ追加」のカスタマイズ機能を使って、汎用認識モデルに必要な単語やフレーズを追加した上で認識性能を評価するところからスタートすることを推奨しています。

組み込み型 mimi®︎ ASRでは、孤立単語認識器や制限パターン認識器を利用することができます。これらの認識器を、デバイス組み込みではなく弊社クラウドサーバー上に設置することで、クラウド型音声認識 API サービスのように、ネットワークを経由して利用することができるようになります。お客様サーバー上に設置することや、オンプレミス環境への対応も可能ですのでご相談ください。

ログインするだけですぐに mimi®︎ クラウドAIを無償評価利用することができます。
プログラミングの知識不要。APIコンソールでは簡単な画面で試すことができます。
mimi®には、クラウド上で高度な認識処理を行うクラウドAIと、
デバイス上で高速な前段処理を行うエッジAIがあります。
mimi®︎の全体像や、mimi®︎エッジAIについて知りたい方はこちら。
 APIコンソール
APIコンソール mimi ASRの
mimi ASRの