ビジネス現場において、対話が発生する箇所は数多くあります。近年一般的となったビデオ会議システムや、窓口での業務補助・記録保存など現場での対話業務を支援するソリューションを提供しています。



音声翻訳ソリューションは多言語への翻訳をメインとしており、音声UI構築ソリューションはチャットボットを利用した人間と機械の対話システムをメインとしています。対話業務支援ソリューションでは、人間と人間の対話に音声システムを導入することで、現場業務の効率化を実現します。 代表的な事例として、ビデオ鍵システム、窓口対話システム、インタビュー支援システムの事例をご紹介します。

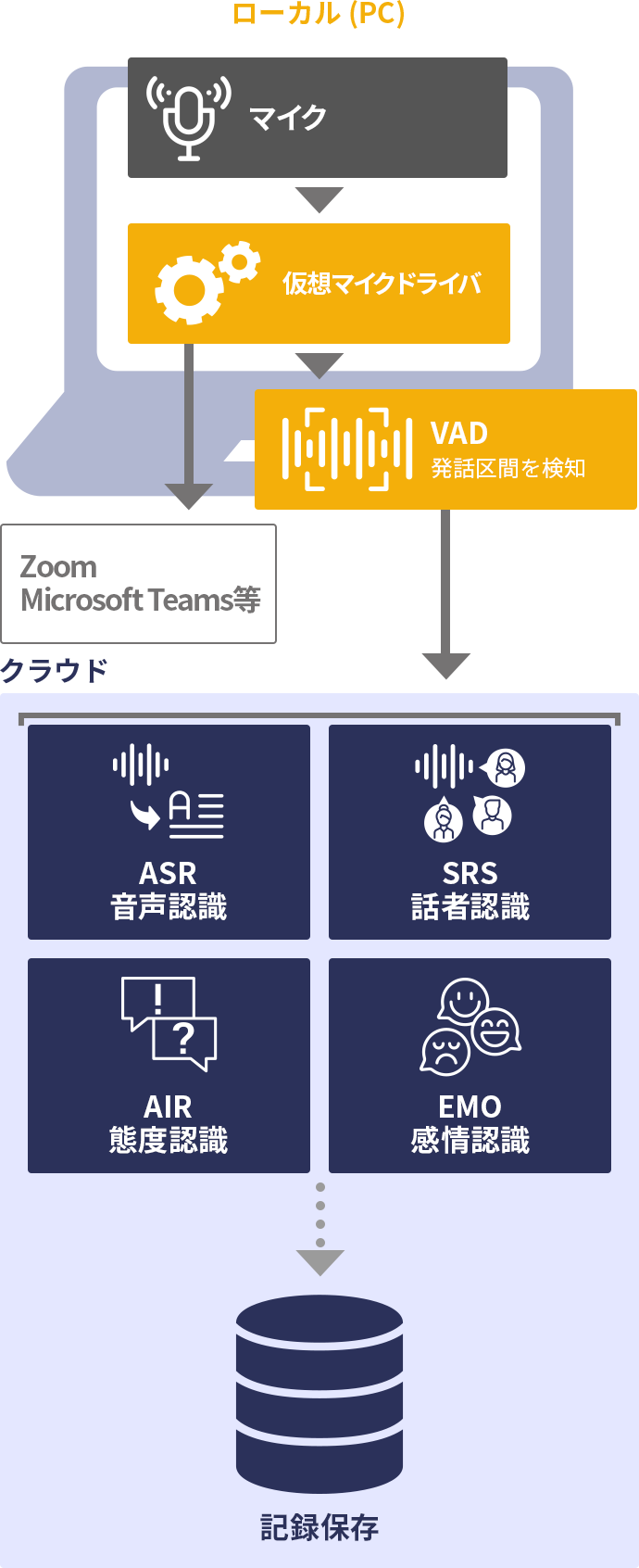
近年、ZOOM や Microsoft Teams 等のビデオ会議サービスが幅広く普及しています。ビデオ会議サービス内に音声や映像を保存したり、それを文字化する機能が搭載されているものもありますが、多言語対応に差があったり、専門用語の認識性能が不十分であったりする場合があります。また、記録された映像や音声を後日利活用するために、重量級のシステム開発が必要になってしまう事例もあります。
このようなときに、当社の 仮想マイクドライバを利用したシステムが有効です。パソコンの物理マイクで収録された音声は、まず仮想マイクドライバに渡されます(上図緑色部分)。仮想マイクドライバは、ビデオ会議システムから見ると、ひとつのマイクとして見えています。ビデオ会議システムのアプリケーションのマイクの設定から仮想マイクドライバを選択すると、物理マイクの音声が素通しされてビデオ会議システムに渡されるため、通常通りビデオ会議サービスを利用することができます。
この裏側で並行して、仮想マイクドライバはその内部でクラウドと通信することができ、音声認識、話者識別、感情認識等、必要な認識を行うことができます。それらの結果をパソコンで閲覧・保存することや、別のクラウドシステムに転送して保存することも可能です。クラウドに接続できない環境であれば、パソコンのローカルシステムでこれらの認識を行うこともできます。
ビデオ会議システム側で参加者ごとに書き起こしができている場合も、リアル会場側に複数人がいるケースでは、リアル会場側で「誰が」発話したかを識別するために話者識別機能を利用するなどして、ビデオ会議システムの書き起こし記録と組み合わせて利用することも有効です。
仮想マイクドライバに接続される物理マイクは、パソコンに搭載されているマイクだけではなく、一般の USB マイクや、当社製マイクアレイのTシリーズを利用することもできます。マイクアレイを利用する場合は、上図緑色部分に XFE を搭載します。
この方式では、ビデオ会議システムに渡される前の音声をキャプチャーしているため、後段のビデオ会議システムが何であっても利用することができるという汎用的なシステムを構築することができます。また、ビデオ会議サービスの流儀によらずして音声を蓄積して利活用できるため、自社のナレッジマネジメントシステムに統合するなどの応用的な利活用が促進されます。
この構成例は、音声翻訳ソリューションのビデオ会議システムの構成例と類似例ですが、合成音声を使わない分、リアルタイム性の制約が小さく、より応用範囲が広い構成例であると言えます。

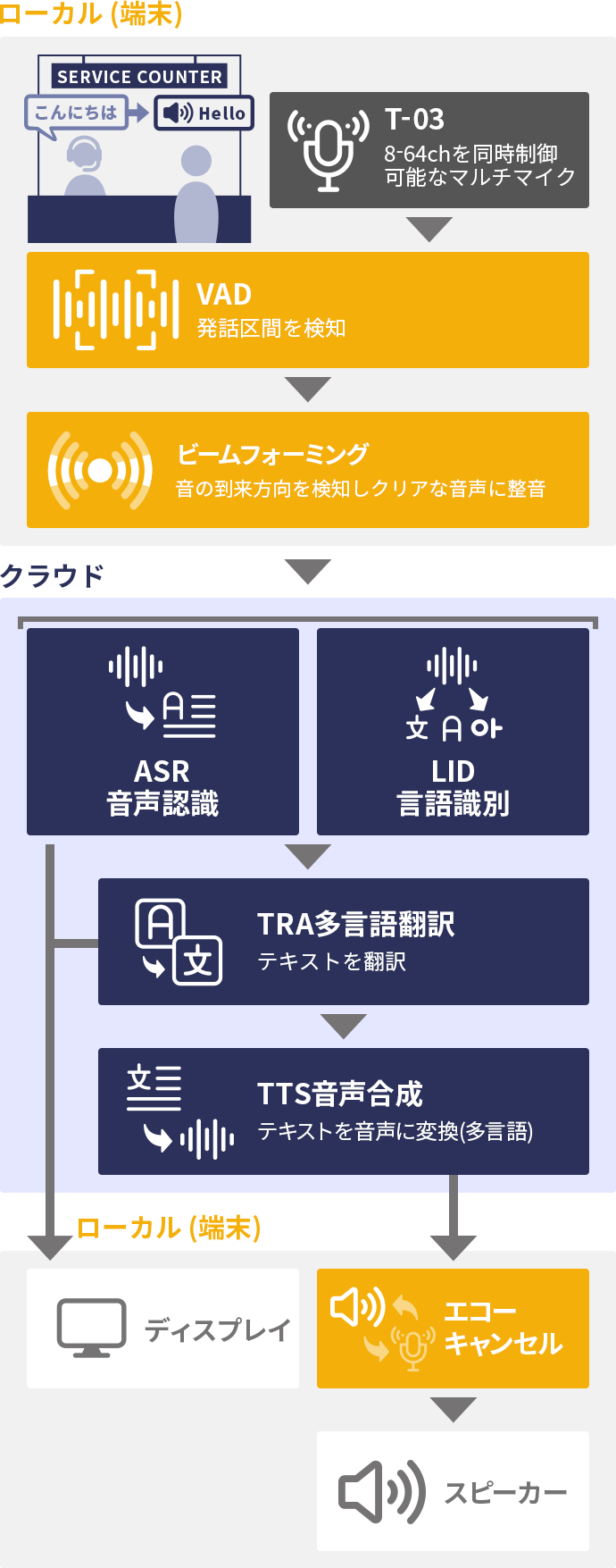
この構成例は、音声翻訳ソリューションの窓口翻訳システム とほぼ同じ構成例であり、構成のポイントについては、そちらもを合わせてご覧ください。言語識別により機械翻訳が利用できる構成ですが、日本語がメインの環境であれば単に翻訳が実行されないだけです。この構成例では窓口での対話内容を書き起こして保存することができます。
訪日観光客の増加などの国際化の影響で、日本国内にある窓口であっても日本語だけで完結するということは今後ますます少なくなっていくことが見込まれます。窓口翻訳システムと窓口での対話記録は一体のものとして利用することが好ましいといえます。
窓口での対話を記録することで、どのような質問があるのか?どのような要求が多いのか?ということを定量的に把握することができるようになります。そのような定量的なデータは、業務全体の効率化のための基礎データとして利用することができます。コールセンター等で導入されているシステムと同様であり、そのリアル窓口版と言うこともできるシステムです。

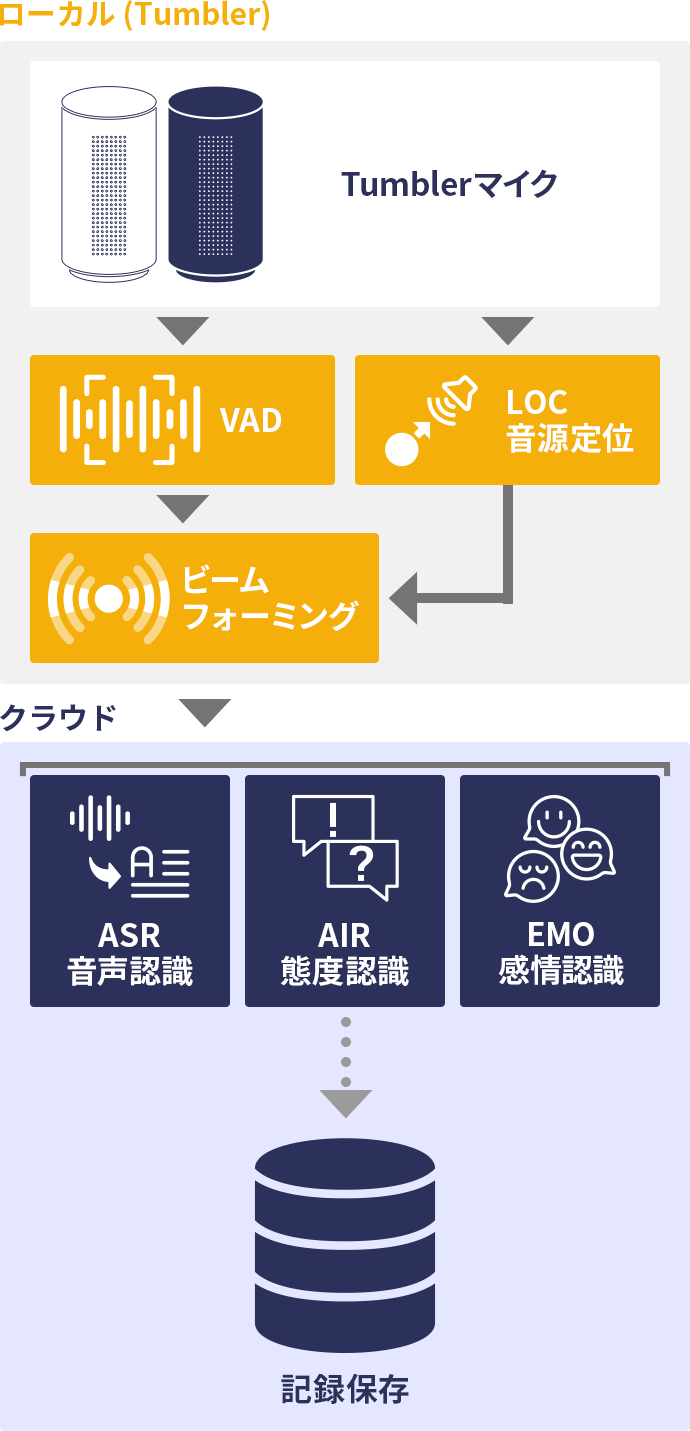
上記の窓口音声対話記録システムと似た構成ですが、当社の Tumbler マイク(T-01) 等のデスクトップ型のマイクアレイを利用することで、インタビューなど少人数で行う対話記録の作成に特化したシステムを構成することができます。
Tumbler マイクを利用する場合、窓口のような 1 対 1 の対話だけではなく、麻雀卓のようにひとつのテーブルを3人または4人が囲むようなシチュエーションで、それぞれの参加者の声を別々に録音することが可能となります。インタビューや面接、グループミーティングのような場面の音声記録に有効です。このテクノロジーデモンストレーションは レコメモ を利用することで体験することができます。
まず、マイクアレイによって集音された多チャンネル音声信号から、音源定位によって、音源の方向が推定されます。次に、推定された音源の方向にビームフォーミング等の音声協調処理を行い、その方向の音声のみを集音し他の方向の雑音を抑圧する処理を行います。 これによって、例えば2人が同時に発話した場合であっても、それぞれの音声を分離して音声認識を行うことができるようになります。
このような音声強調処理は、音声UI構築ソリューションのサービスロボットの構成例や、音声翻訳ソリューションの窓口翻訳システムの構成例のように、屋外や商業施設内等の周辺雑音が大きい場所では必須です。 しかしながら、この構成例の場合は、会議室の中などの静穏環境で利用されることが想定されるため、周辺雑音を抑制するという観点からは、ビームフォーミング等の音声強調処理を必ずしも行う必要はありません。もちろん、その場合には同時に複数の発話があった場合に分離できないという問題が発生しますが、インタビューやグループミーティングの実例で、発話が重なる回数というのは必ずしも多い訳ではなく、そのような場面は捨象してしまうこともひとつの良い割り切りであると言えます。
その理由として、ビームフォーミング等の音声強調処理に足る音源定位性能は、環境によっては必ずしも達成できない場合があるという理由が上げられます。例えば、会議室にアクリルパーティションなどが設置される場合がありますが、パーティション越しの発話の場合には、音源定位性能が劣化する場合があります。別の例として、マイクに背を向けて(例えばホワイトボードの方を向いて)発話するような場合にも、音源定位性能が悪化します。 音源定位に失敗した場合、真の発話方向に安定的にビームを構築することができません。その場合であっても、適切な設計であれば無処理の場合と比較して性能が劣化するということはありませんが、発話のされ方によって同時発話には対応できないケースがあるということは事実であるため、同時発話の分離に失敗したケースへの対応が必要になり、GUI の作りこみを含めて全体システムが複雑になります。レコメモはそのようなケースまで想定して作りこまれていますが、実際には同時発話が起こる回数が多くはないことを鑑みると、必ずしも常に必要であるとは言えません。
ビームフォーミング等の音声強調処理を行わない場合、発話区間抽出された音声はそのまま音声認識が実行されます。別途音源定位が実行され、音源方向が推定されます。音源方向の推定が失敗した場合にも単に音源方向が不明であるというだけで音声認識結果は得られているためシステムとして問題はありません。前述の通り、同時発話に対応できないことと、ビデオ会議システムなど会議室に別のスピーカーがある場合に、そちらの音声に反応して不正確な音声認識結果が出てしまう可能性があることなどのデメリットは残ります。システムのシンプルさを取るか、多様なケースへの対応力を取るかというのは設計上の要点であると言えます。
誰が発話したか?という観点のみであれば、話者識別を利用することも有効です。音源定位の場合は、どの方向から発話されたか?という情報で誰が発話したかということを間接的に推定していました。話者識別を使う場合は、音声データのみから誰の発話であるかを直接的に推定できます。この場合は、別途マイクアレイを利用しなくても、ノートパソコンの内蔵マイクでも実現することが可能でよりシンプルです。詳細については下の囲み記事も合わせてご覧ください。
クラウド側では音声認識だけでなく、音声態度認識や、音声感情認識を組み合わせることで、ミーティングでの対話内容をより詳細に分析することができるようになります。その他にも、誰の発話時間が長かったか?複数人の参加者がいるとき誰と誰がよく対話しているか?誰が質問し誰が答えているか?など、対話を分析するための様々なメソッドが知られています。
最近では、ChatGPT のような大規模言語モデルを利用することで、対話内容を適切に要約することも可能になってきており、ミーティングの参加者それぞれの発言要旨を AI が自動的に要約して記録することができ、この構成例のようなシステムの重要性はますます大きくなってきていると言えるでしょう。
[1] 慣用的に良く言われる「声紋」ですが、指紋のように明確なものとは異なります。テレビ番組などではよく周波数スペクトルを表示してそれがあたかも声紋であるかのように表現していますが、それは単なるスペクトルであって、直ちに話者を識別できるものではありません。つまり、そこから何らかの特徴量が得られて、その特徴ベクトルこそが声紋足り得る存在であると理解する方が現代的ではないでしょうか。これは、話者識別の研究の世界では「話者ベクトル」と呼ばれるもので、この話者ベクトルの中身はディープラーニング技術の発展に伴ってより洗練されたものとなっています。
[2] 発話区間抽出器(Voice Activity Detector)、略称VADが利用されます。入力音声に含まれる無音の時間などを手掛かりに、長い音声から発話区間を抽出していきます。当社でも XFE ライブラリの VAD モジュールとして提供しています。
[3] これは当然のことであるように思われますが、ナイーブに実装すると最も似た声質の話者を返すという仕組みになってしまい、実用上の問題が発生します。登録外の話者であるということを判定するためには話者識別器に工夫が必要です。
[4] 会議システムを通することで音声が劣化し、会議室のパソコンもしくはモニターのスピーカーから再生されることでさらに劣化し、さらにそのスピーカーとマイクアレイとの間には通常数メートル程度の距離があるため、その距離によっても音声認識率は低下します。このため、会議システムの音声は会議システム側(もしくは仮想オーディオドライバを組み込んだローカル側)で認識することが好ましいといえ、スピーカーから会議室に再生された音声を利用するべきではありません。

多言語対応の音声案内サイネージに利用可能です。外国人観光客等が、何の事前準備もなく、単にサイネージに話しかけるだけで動作するため、直観的に利用してもらうことができます。

多くの機械翻訳専門アプリがありますが、そういった専門アプリの開発だけでなく、自社アプリの中に翻訳機能を埋め込む等の付加価値向上が可能です。チャットツールへの翻訳機能の追加は特に利便性を高めます。

バスやタクシー等の座席に設置されているタブレット端末を多言語音声対応させることが可能です。特に XFE と組み合わせることで、車内の走行音等を抑制し高精度な音声認識を実現することができます。

小型で持ち歩ける翻訳専用端末などを利用することもできますが、透明ディスプレイやタブレット端末等の窓口に設置できるタイプの非接触型翻訳システムとして利用することができます。

ウェブ会議システムでは、ベンダーが翻訳機能を組み込んで提供している場合も多くありますが、翻訳機能のないウェブ会議システムや、独自の WebRTC ベースの通信システム等に外部的に音声翻訳機能を付与することができます。

導入事例
mimiエッジAIとクラウドAIの多くの機能を活用した駅構内・周辺案内業務用コミュニケーションロボットです。多くの人が行きかう雑踏騒音環境でも、目の前の人の声だけを聞き取り正確な応答を実現しています。話しかけた言語は自動で識別され、多言語での応答を行うことができます。これにより駅員の質問対応業務時間を削減することに成功しました。
オムロンソーシアルソリューションズ株式会社
詳しく見る
導入事例
mimiエッジAIとクラウドAIの多くの機能を活用したデジタルサイネージ向けの音声対話システムです。多くの人が行きかう雑踏騒音環境でも、目の前の人の声だけを高速かつ正確に聞き取り、画面表示と連動した分かりやすく親しみやすい応答を実現しています。
株式会社モノゴコロ
詳しく見る