当社の技術部門は、製品開発部と研究開発部からなります。研究開発部が基礎・応用研究を担い、製品開発部は研究成果の製品化を担います。当社で製品化を行う研究成果は、自社成果に加え、NICT などの外部研究機関の成果や、外部共同研究先企業の成果を含みます。当社技術部門は自社製品開発を主力業務としつつも、専門技術を活かして、お客様の先進的な製品開発をお手伝いする業務も行っております。これまでお客様と共に開発した製品は数十製品に及び、コンシューマー製品からエンタープライズ機器、コミュニケーションロボットなど多岐に渡り、お客様の累計販売台数は300万台を超えています。





最適な音声 UX を実現するためには、ハードウェア層からサービス層まで一気通貫した設計が重要です。当社では、必要な要素技術・ノウハウの多くを既に保有しておりますので、大半のニーズには迅速に応えることができます。当社で保有している技術群でも足りない場合には、外部研究機関や外部共同研究先が保有している知財・技術にアクセスすることができます。その上で、より難しい問題に取り組まなければならないときには、研究レベルから取り組むことも可能です。研究レベルからの取り組みには、数か月から1年程度の期間と費用がかかりますが、お客様の実務ニーズに寄り添った研究活動を展開することができますので、期待される成果に対して無駄のないコストで取り組むことが可能です。
当社の研究開発部は、自社研究成果を継続的に世界トップクラスの査読付き雑誌・学会に発表しています。代表的な業績は以下の通りです。最先端研究に従事する研究者が、お客様の製品開発をお手伝いすることができます。
当社の専門性を活かした代表的な受託・共同開発の類型には以下のようなものがあります。この類型は代表的なものであり、この類型以外の内容につきましても取り組み実績があるものもございますので、お気軽にお問合せください。
様々な環境で利用される音声機器の開発を行ってきました。その成果の一部は、T シリーズマイクアレイや、THINKLET®︎ などの独自ハードウェアとして製品化されておりますが、その他にも、音声操作に対応した家電製品やデジタルサイネージ、一世を風靡した某音声対話ロボットや、駅案内ロボットなど数多くの共同開発の実績があります。モバイル機器においても、スマートフォン、THINKLET®︎ のようなウェアラブル端末や、完全無線イヤホン・ヘッドセットなどに当社技術を提供して参りました。
特に、家電製品・デジタルサイネージやロボットなどの大型機器においては、どのようなマイクアレイを利用するかということが極めて重要であり、T シリーズを利用せず、お客様独自のハードウェアを設計する場合にも、コスト制約の範囲で所望の性能を達成するためには、検討するべき事項が数多くあります。お客様のご要望に合わせて、最適なアドバイスとコンサルティングを提供いたします。
mimi® は、10年以上に渡りお客様からの要望に基づいて様々な認識技術を開発してきた技術群の集大成です。多くの標準サービスがすぐに利用できる形で提供されており、実製品で典型的に使われるカスタマイズ機能も提供されています。
しかしながら、標準サービス+カスタマイズでは対応できないニーズもあります。例えば、mimi® EMO では「カスタム感情認識」を定義することができます。「時間が足りず焦っている気持ち」など具体的な業務に特化した「感情」を認識するといったものですが、このような取り組みでは、お客様と協働して学習データを準備し、実地で性能を評価し、アルゴリズムを調整するといった取り組みが必要となります。感情認識のための基本アルゴリズムは弊社で既に構築されたものを利用するため、学習データを準備し、アルゴリズムを調整することなどで実現することができますが、研究者が直接作業を行う必要がある活動であり、カスタマイズ機能としてパッケージとして提供できるような性質ではありません。
カスタム感情認識においては、感情認識のための基本アルゴリズムは既に構築済みですが、そのような基本アルゴリズムが未開発の場合もあります。音声データから何らかの知見を発見・抽出するという観点では、mimi® では既に数多くの技術資産を保有していますので使いまわせる場合が大半ですが、特に難しい問題に取り組まなければならない場合などで、アカデミアでの最先端の研究成果を適用したいときなどには、基本アルゴリズムの研究開発評価を行う必要があるでしょう。
従来から mimi® はそのような取り組みによって作られてきたものですので、このような応用基礎レベルから研究開発に取り組むことも可能です。知的財産の取り扱いについても柔軟にご相談を承ることができます。

近年、個⼈⽤・家庭⽤・産業⽤など幅広い⽤途において、⾳声対話システムの重要性が増しています。その⼀⽅で、⾳声対話システムの開発は技術的側⾯・⼈の⼼理的側⾯などさまざまな要因が絡んだ困難なチャレンジであり、誰でも容易に開発できるとは⾔いがたい状況です。
ここでは、特にビジネス⽬的で製品化に向けて⾳声対話システムを開発する場合の、典型的なプロセスを紹介します。(実際の開発はそれぞれ状況が異なり、ここで紹介する典型例とは相違が発生する可能性があります。)
以下の図は典型的な音声対話システムの開発プロセスを示しています。
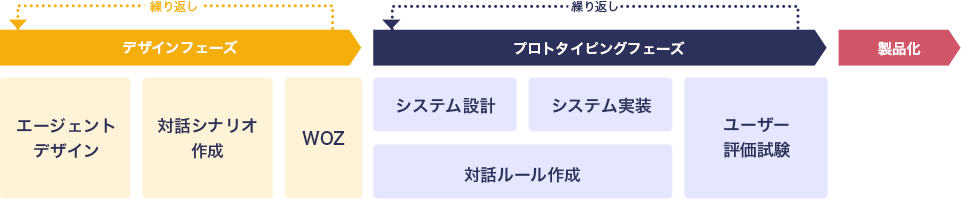
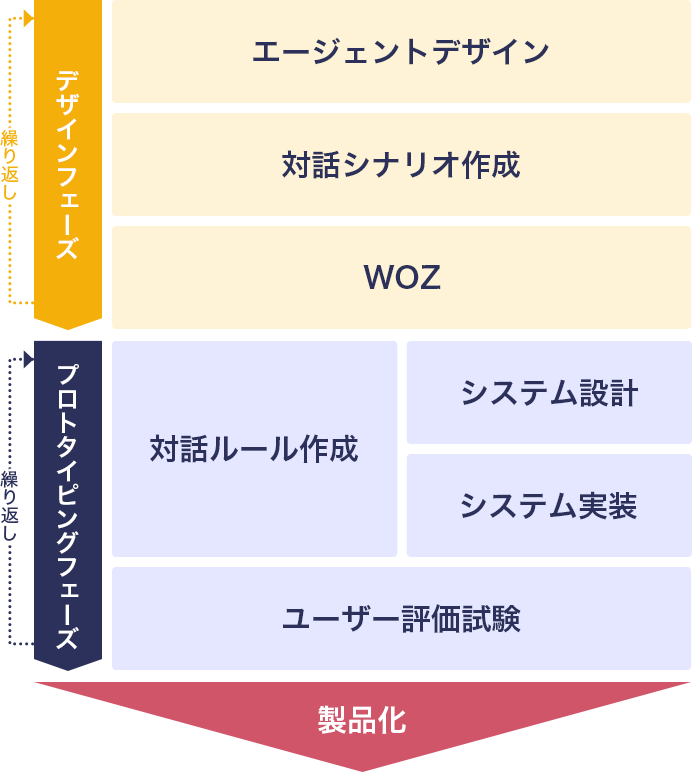
図1. 典型的な音声対話システムの開発プロセス
初めに、⾳声対話システムの⽬的(果たすべき役割、実現するべき価値)を定めます。その上で、システムそのものの「⼈格」である「エージェント」のデザインを⾏います。
エージェントはユーザーの印象や期待を裏切らないことが重要です。そのため、「ペルソナ」・「ボディ」・「アビリティ」の3要素の⼀貫性を保ちつつ、現在の技術⽔準において実現可能なものであるかどうかを検証しながらデザインしていきます。
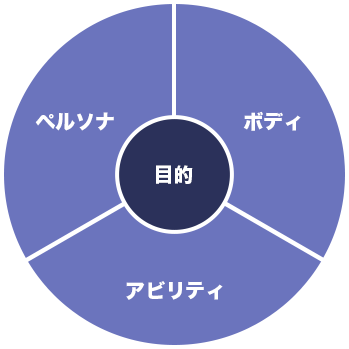
図2. エージェントデザインの3要素
ペルソナ
エージェントの性格特性。
システムの基本的な振る舞いを
規定します。
ボディ
エージェントの外見。
ユーザーに提供するインタフェースと
コミュニケーション手段を規定します。
アビリティ
エージェントの能力。
システムが実行可能なサービス内容を規定します。
エージェントのデザインに沿って対話ルールの基本的な枠組みを決定し、ユーザー試験のための台本(対話シナリオ)を作成します。例えばインテンション・スロットという枠組みでは、⼊⼒(ユーザー発話)・出⼒(システムの応答)とこれらの⼊出⼒を決定するルールを考えて、対話シナリオを作成していきます。
決定したデザインの妥当性を検証します。この時点では⾳声対話システムの実物はまだありませんので、実際の利用環境に近づけたモックのシステムを用意し、システムの役割を⼈間が担うWizard of Oz (WOZ)
⽅式のユーザー評価試験を⾏います。WOZによってエージェントデザインが適切でシステムの目的に則しているかどうか、およびこの時点で期待する水準に達しているかどうかを評価します。WOZの結果、エージェントデザインが一貫していない・技術的な妥当性がない・あるいは目的に沿っていないことが判明した場合はデザインをやりなおし、妥当なデザインであることが確かめられるまで以上のデザインフェーズを繰り返し⾏います。
デザインフェーズが完了したら、続いて実際に動作するプロトタイピング版の開発に進みます。
デザインフェーズで作成した基本的な対話ルールを拡張し、ユーザーの利用状況に即した網羅的な対話ルールを作成していきます。
典型的な⾳声対話システムの構成は以下のようになります。エージェントデザイン、およびシステムの⽬的と利⽤状況に基づいて、論理的に設計していきます。

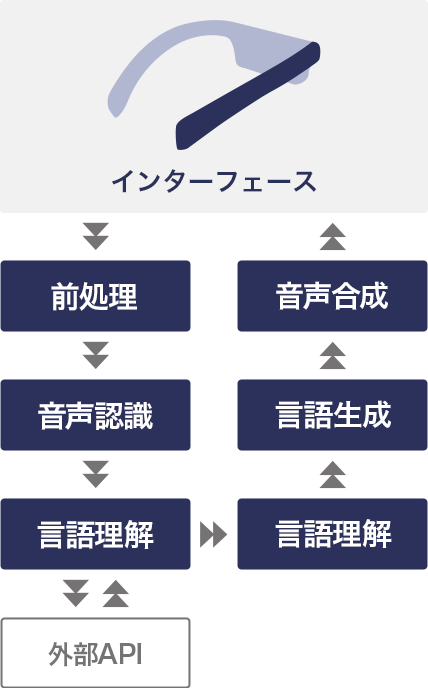
図3. 典型的なシステム構成
⾳声対話システムはさまざまな要素技術を必要とします。ユーザーインターフェースの役割を果たすハードウェア本体、及びクラウド上の計算資源の割り当て、ソフトウェア構成、そして機械学習のモデルやアルゴリズムを、各々の選択肢の特性、期待される性能、準備するためのコスト、メンテナンス性などを考慮して決定していきます。
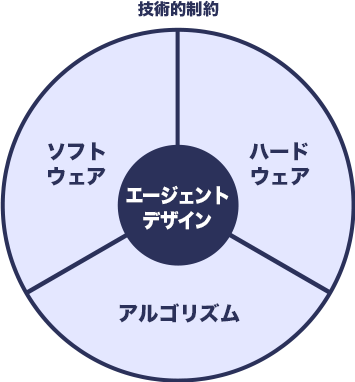
図4. システム設計の3要素
期待した性能水準を達成するまでプロトタイピングフェーズを繰り返し行い、達成した時点で製品版の開発に進みます。 本フェーズの内容は通常のシステム開発と同様です。ただし製品版において要求される安定性、セキュリティ、スケール性、メンテナンス性などの⽔準を満たすように設計の修正を⾏う必要があります。